Projects
The research in the Vertical group spans VLSI technology to software and application analysis. Such an integrated approach is necessary to design future high performance systems. Our research focuses on future systems targeting a 2030 time-frame considering three broad directions:
- With the end of Moore's Law, what is the role of architecture in the economics of the semi-conductor industry
- What should be the boundary between software engineering and the compiler
- What should be the boundary between the compiler and architecture
- What should be the boundary between architecture and microarchitecture
The OnePercentChip Project

In the OnePercentChip Project we are exploring the limits of Amdahl's law and how it ties to hardware specialization. In particular, when extreme amounts of speedup are needed 50X to 100X or more, then extreme attention needs to be paid to the common case and the uncommon case. In particular, from a productivity and standpoint of completely working system for real applications, attention needs to be paid to whether the architecture is compilable, whether the compiler is sufficiently agile to fit in a standard software engineering flow, and whether the extreme speedups are actually realizable when various physical constraints are taken into account. We are looking at AI and Deep Learning to seed some of the ideas - the end goal of the project is to create a workload/domain-agnostic blueprint.
Student Crowd Sourced Textbook
In our introductory sophomore level course on computer architecture we cover basic boolean algebra, number representation, arithmetic, fixed-point, floating-point, transistor behavior, logic gates, datapath (adder, multiplier), finite state machines, assembly language, and a simple processor. I am developing an interactive textbook for this material built on RISCV for the processor, with each module have an interactive simulator. The course would be taught with near minimal "lecturing" instead by working on assignments and doing things on this simulator. All material developed will on a GPL license and free to use in source code form by anyone else. Interested to contribute - email me.
SimpleMachines

The ideas from the Exocore project led to SimpleMachines which was founded in early 2017 by Karu. It includes several core members from the Exocore and MIAOW project as part of the founding team including Vinay Gangadhar, Preyas Shah, Tony Nowatzki, Ziliang Guo, and Simon Xu. More on SimpleMachines is on the website.
Completed Projects
- Exocore Project (2013-2020)
- MIAOW Project (2012-2015)
- XAPP Project (2012-2015)
- Relax Project: Exposing hardware reliability (2008 - 2015)
- Idempotence Project: Revisiting microarchitecture (2011-2015)
- DySER Project: Hardware specialization (2010-2015)
- ISA Wars Project (2012)
- Dark Silicon Project (2010-2012)
- PLUG Project (2009-2015)
Exocore Project (2013-2020)
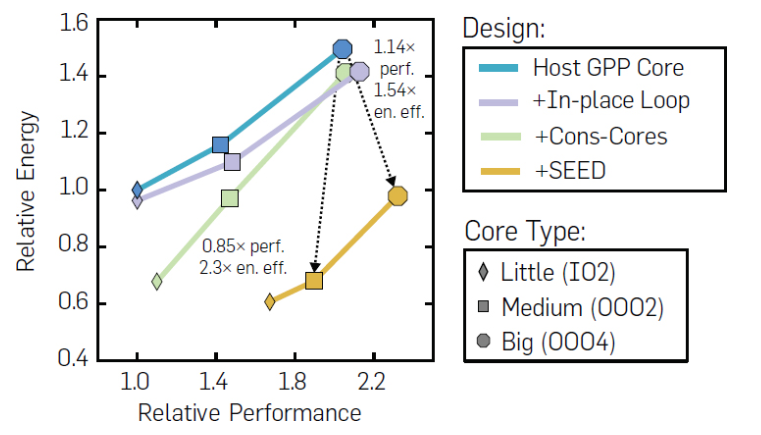
The Exocore project revisits the fundamental ideas of what it means to do specialized computing. In particular it explores the spectrum of von Neuman processing and dataflow processing, the paradigm of behavior specialized execution, how to develop compilers that are substantially separated from the architecture, thus allowing them to be re-targeted to different architectures.
Tools
We developed the TDG (transformable dependence graph) framework and the ILP compiler. The ILP compiler is available on our tools page. The TDG framework from our ASPLOS 2016 is available on request .
People
- Tony Nowatzki
- Vinay Gangadhar
- Newsha Ardalani
- Michael Sartin-Tarm
- Lorenzo De Carli
- Cristian Estan
- Behnam Robatmili
Publications
- Stream-Dataflow Acceleration ISCA 2017. pdf
- HPCA 2015 Pushing the Limits of Generality. pdf
- ISCA 2015 Hybrid Von-Neumann/Dataflow. pdf
- PLDI 2013 ILP Compiler paper. pdf
- See full publication list here.
MIAOW Project (2012-2015)
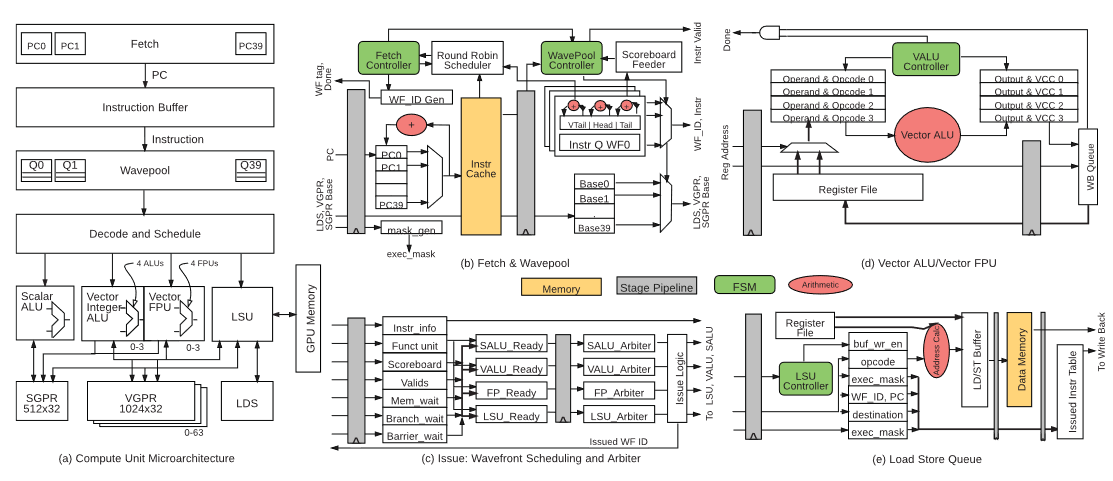
The MIAOW Project's goal was simple: build an open source hardware GPU. It was driven by AMD's release of their backend ISA which allowed substantially portions of the complete software stack to be available for a new hardware implementation. The goal was to explore the limits of what could be done by a small team. We got a fully working solution and talks at COOLCHIPS and HOTCHIPS. Going to Yokohama Japan for COOLCHIPS was an addded perk of working on this project!
Tools
The entire RTL, verification infrastructure and documentation is on github here
People
- Raghuraman Balasubramanian
- Tyler Chamberlain
- Mario Paulo Drumond
- Vinay Gangadhar
- Ziliang Guo
- Chen-Han Ho
- Zuodian Hu
- William Jen
- Cherin Joseph
- Jaikrishnan Menon
- Robin Paul
- Sharath Prasad
- Peter Procek
- Tianshuo "Stanso" Su
- Pradip Vallathol
- Shunmiao Xu
Publications
- HOTCHIPS Paper. pdf
- See full publication list here.
XAPP Project (2012-2015)
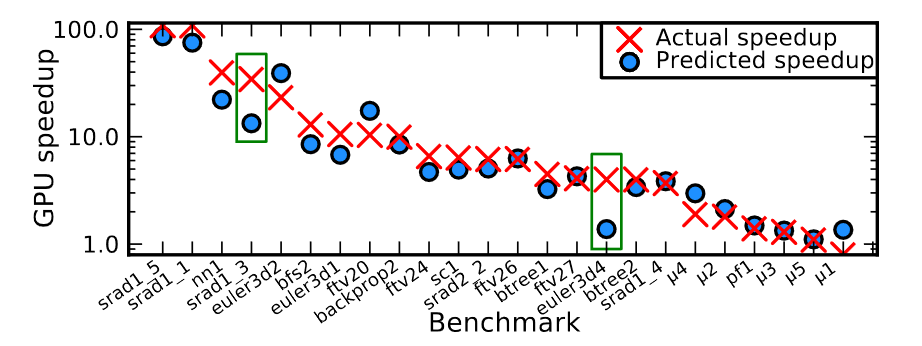
In the XAPP Project we introduce the concept of cross-architecture performance modeling, particularly for CPU to GPU platforms. Cross-architecture performance modeling has the potential to enhance the programmers� productivity, as it is orders of magnitude faster than the existing norm of porting code from one platform to another, and can be used to improve programmers� productivity; Having one performance model per accelerator can help to find the best accelerator and the best algorithm before spending many engineering hours down each path.
People
- Newsha Ardalani
- Clint Lesturgeon
- Xiaojin Zhu
- Urmish Thakker
- Aws Albarghouthi
Publications
- XAPP Micro 2015 paper. pdf
- See full publication list here.
Relax Project: Exposing hardware reliability (2008 - 2015)
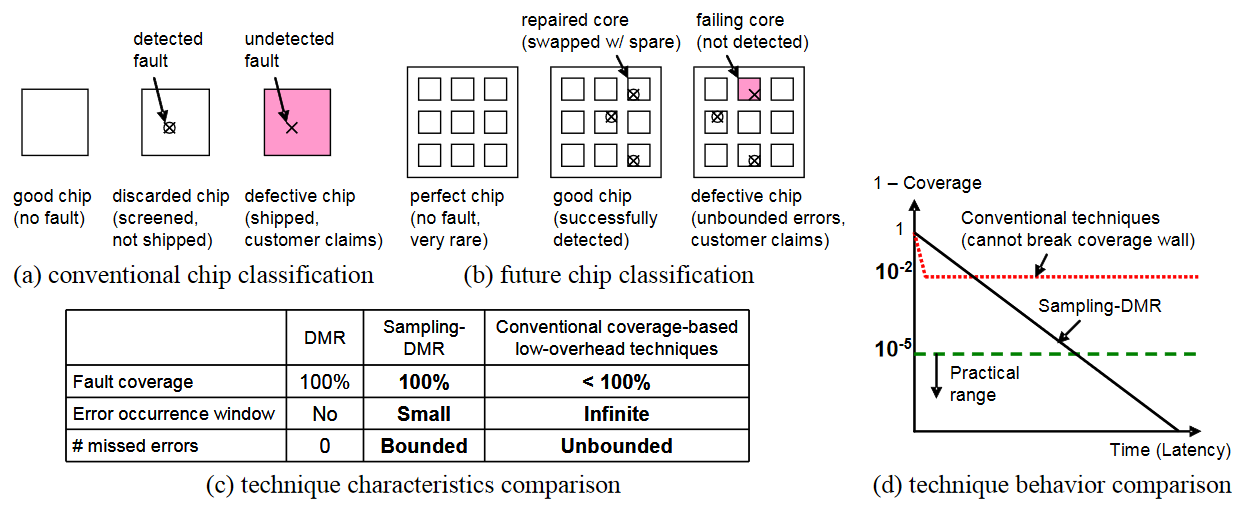
Devices are becoming increasingly brittle, highly varying in their properties, and error-prone, leading to a fundamentally unpredictable hardware substrate. The model of hardware being correct all the time, on all regions of chip, and forever, becomes prohibitively expensive to maintain. Emerging new classes of applications are increasingly relying on probabilistic methods. They have an inherent tolerance for uncertainty, do not require hardware to be correct all the time, and this provides an opportunity to creatively utilize hardware. We are investigating ways to expose hardware reliability at the device level through layers of the system stack up to the application. We are building system software, architecture, and microarchitectural mechanisms that can scale to future technologies.
People
- Marc de Kruijf
- Shuou Nomura
- Raghuraman Balasubramanian
- Chen-Han Ho
- Garret Staus
- Aaron Ullmer
Publications
- PERSim Framework. HPCA 2014. pdf
- Virtually Aged Sampling-DMR. MICRO 2013 pdf
- Sampling + DMR: Practical and Low-overhead Permanent Fault Detection, ISCA 2011, pdf
- Relax: An Architectural Framework for Software Recovery of Hardware Faults, ISCA 2010, pdf
- A Unified Model for Timing Speculation: Evaluating the Impact of Technology Scaling, CMOS Design Style, and Fault Recovery Mechanism. DSN 2010, pdf
- See full publication list here.
Idempotence Project: Revisiting microarchitecture (2011-2015)
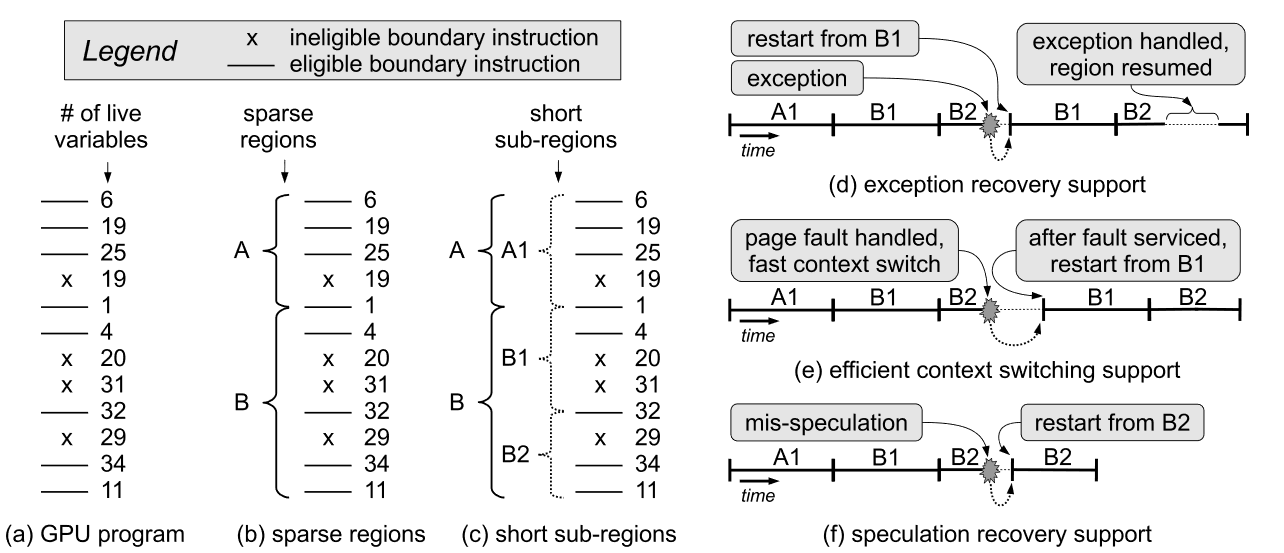
We are revisiting some of the fundamental principles of processor microarchitecture design in the light of energy and reliability becoming primary constraints. In the Idempotence project, we observe that the mathematical property of idempotence which allows an operation to be performed multiple times producing the same results provides a powerful and elegant way to radically simplify and eliminate many hardware structures. The ideas of idempotence allow exception support in GPUs, concurrency bug recovery, and several other foundational uses.
Tools
One of the outcomes of our Idempotence work is our iCompiler which is an LLVM-based compiler that outputs programs that are continuous idempotent regions. The tools pages for the iCompiler is here.
People
- Marc de Kruijf
- Shuou Nomura
- Chen-Han Ho
- Jai Menon
- Shan Lu
- Yuxi Chen
- Shu Wang
- Somesh Jha
Publications
- iGPU: Exception Support and Speculative Execution on GPUs, ISCA 2012, pdf
- Static Analysis and Compiler Implementation of Idempotent Processing, PLDI 2012, pdf
- Idempotent Processor Architecture, MICRO 2011, pdf
- See full publication list here.
DySER Project: Hardware specialization (2010-2015)
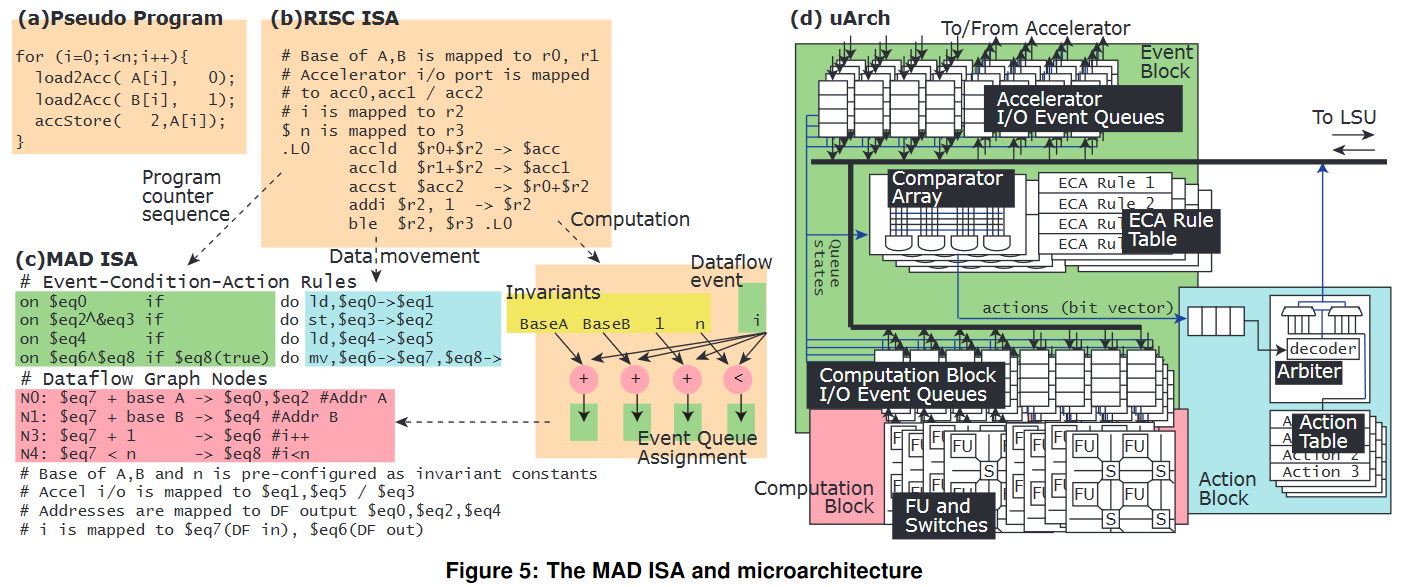
The DySER project complements the Idempotence project in looking at ways to complement the core and specialize it various ways based on the underlying workload. Our DySER prototype RTL design and compiler should be available for download soon. The motivation for DySER was our early work on building a specialized multi-core architecture for ray tracing.
Tools
We have released our compiler and simulator for the entire DySER toolchain. Including the SPARC-based toolchain and the x86 toolchain. The SPARC compiler is slightly less sophisticated than the x86 compiler. On the other hand this toolchain includes our entire verilog and tutorials for FPGA bringup etc. Available here
People
- Chen-Han Ho
- Venkatraman Govindaraju
- Tony Nowatzki
- Ranjini Nagaraju
- Zachary Marzec
- Preeti Agarwal
- Chris Frericks
- Ryan Cofell
Publications
- Efficient Execution of Memory Access Phases Using Dataflow Specialization. ISCA 2015 pdf
- Design, Integration, and Implementation of the DySER Hardware Accelerator into OpenSPARC, HPCA 2012, pdf
- Dynamically Specialized Datapaths for Energy Efficient Computing, HPCA 2011, pdf
- Toward A Multicore Architecture for Real-time Raytracing, MICRO-41, 2008, pdf
- See full publication list here.
ISA Wars Project (2012)
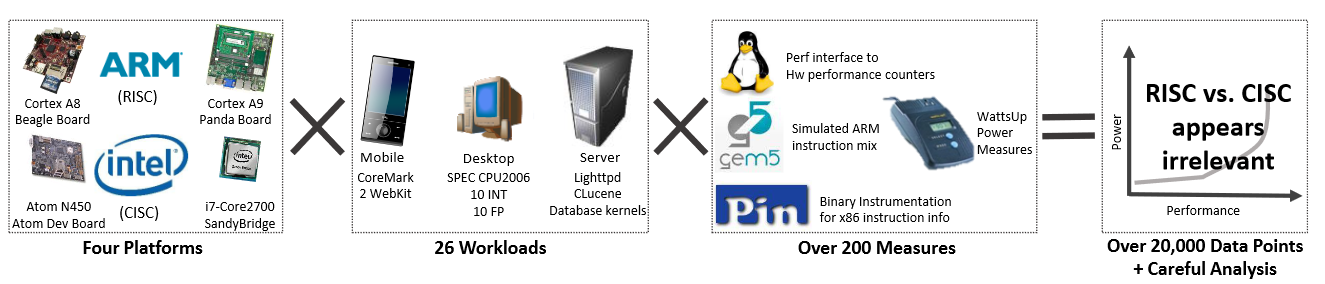
In the ISA Wars project we revisit long-held assumptions on the role of ISA and its relationship to the microarchitecture. The goal was driven without any agenda. Does the ISA matter in terms of what performance and power efficiency can be achieved. Our paper in 2013, showed that the ISA doesn't matter. With recent trends in 2020 with Apple showing extreme performance using ARM, Amazon building ARM servers, at the same time AMD showing extreme performance with the Epyc line, our finding that the ISA is irrelevant seems to be strongly validated. Indeed some of the ideas of RISC-V and open-source ISAs are relevant - they tackle largely a business question and not a technical one.
Tools
Our detailed data is available for download here.
People
- Emily Blem
- Jai Menon
- Vijayraghavan Thiruvengadam
Publications
- Power Struggles HPCA 2013 paper pdf
- See full publication list here.
Dark Silicon Project (2010-2012)
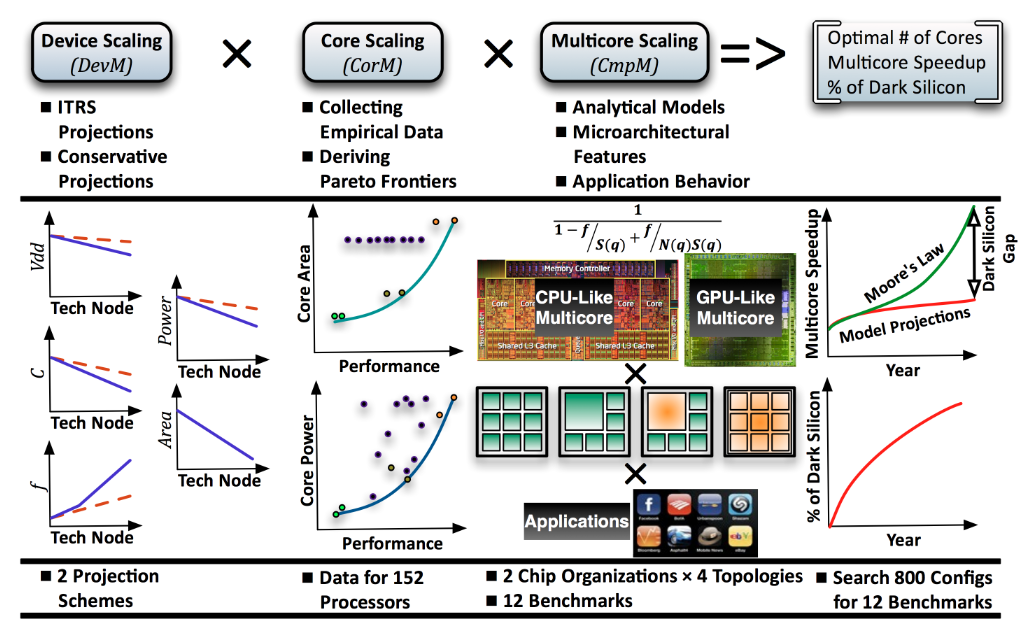
In the Dark Silicon Project we looked at the fundamental limits of transistors, how they scale, detailed tradeoffs on microarchitecture and how it impacts performance and power consumption. Using insightful models, validated against historical data, we were able to project that multicore CPUs would hit roadblocks in performance.
People
- Emily Blem
- Hadi Esmaeilzadeh
- Renee St. Amant
- Doug Burger
Publications
- Dark Silicon ISCA 2011 paper. pdf
- See full publication list here.
PLUG Project (2009-2015)
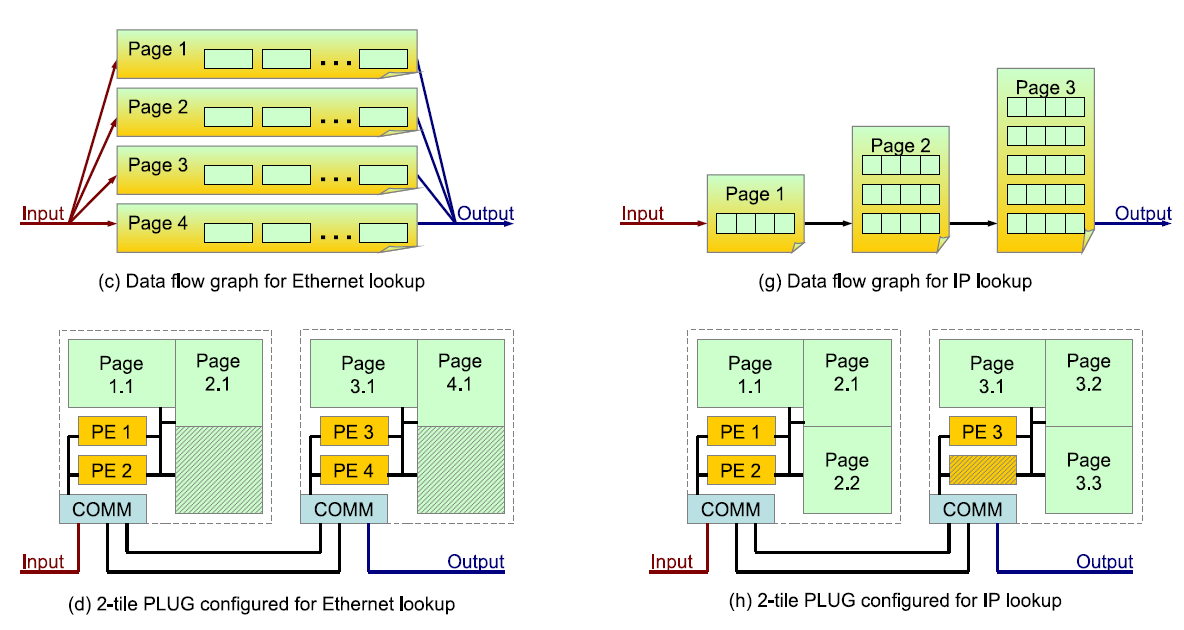
In the PLUG project we looked at how to build a class of architectures that are programmable yet as efficient as ASICs for network processing. The motivation was driven the trends of software defined networking. We looked at architecture at various different parts of the network stack, and some radical hardware solutions that included 3D stacked memory.
People
- Lorenzo De Carli
- Thiruvengadam Vijayaraghavan
- Eric Harris
- Samuel Wasmundt
- Sung Jin Kim
- Yi Pan
- Amit Kumar
- Cristian Estan
Publications
- PLUG SIGCOMM 09 paper pdf
- Near-Memory Data Services. IEEE Micro, 2016.
- Memory processing units. HOTCHIPS 2014 Poster pdf
- See full publication list here.