A directed acyclic graph (DAG) can be used to represent a set of computations where the input, output, or execution of one or more computations is dependent on one or more other computations. The computations are nodes (vertices) in the graph, and the edges (arcs) identify the dependencies. Condor finds machines for the execution of programs, but it does not schedule programs based on dependencies. The Directed Acyclic Graph Manager (DAGMan) is a meta-scheduler for the execution of programs (computations). DAGMan submits the programs to Condor in an order represented by a DAG and processes the results. A DAG input file describes the DAG, and further submit description file(s) are used by DAGMan when submitting programs to run under Condor.
DAGMan is itself executed as a scheduler universe job within Condor. As DAGMan submits programs, it monitors log file(s) to enforce the ordering required within the DAG. DAGMan is also responsible for scheduling, recovery, and reporting on the set of programs submitted to Condor.
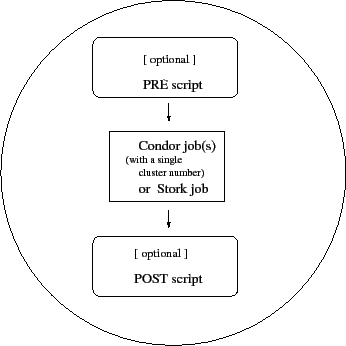
To DAGMan, a node in a DAG may encompass more than a single program submitted to run under Condor. Figure 2.1 illustrates the elements of a node.
At one time, the number of Condor jobs per node was restricted to one. This restriction is now relaxed such that all Condor jobs within a node must share a single cluster number. See the condor_submit manual page for a further definition of a cluster. A limitation exists such that all jobs within the single cluster must use the same log file. Separate nodes within a DAG may use different log files.
As DAGMan schedules and submits jobs within nodes to Condor, these jobs are defined to succeed or fail based on their return values. This success or failure is propagated in well-defined ways to the level of a node within a DAG. Further progression of computation (towards completing the DAG) may be defined based upon the success or failure of one or more nodes.
The failure of a single job within a cluster of multiple jobs (within a single node) causes the entire cluster of jobs to fail. Any other jobs within the failed cluster of jobs are immediately removed. Each node within a DAG is further defined to succeed or fail, based upon the return values of a PRE script, the job(s) within the cluster, and/or a POST script.
The input file used by DAGMan is called a DAG input file. All items are optional, but there must be at least one JOB or DATA item.
Comments may be placed in the DAG input file.
The pound character (#) as the first character on a
line identifies the line as a comment.
Comments do not span lines.
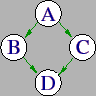
A simple diamond-shaped DAG, as shown in Figure 2.2 is presented as a starting point for examples. This DAG contains 4 nodes.
A very simple DAG input file for this diamond-shaped DAG is
# File name: diamond.dag
#
JOB A A.condor
JOB B B.condor
JOB C C.condor
JOB D D.condor
PARENT A CHILD B C
PARENT B C CHILD D
A set of basic key words appearing in a DAG input file is described below.
The JOB key word specifies a job to be managed by Condor. The syntax used for each JOB entry is
JOB JobName SubmitDescriptionFileName [DIR directory] [NOOP] [DONE]
A JOB entry maps a JobName to a Condor submit description file. The JobName uniquely identifies nodes within the DAGMan input file and in output messages. Note that the name for each node within the DAG must be unique.
The key words JOB, DIR, NOOP, and DONE are not case sensitive. Therefore, DONE, Done, and done are all equivalent. The values defined for JobName and SubmitDescriptionFileName are case sensitive, as file names in the Unix file system are case sensitive. The JobName can be any string that contains no white space, except for the strings PARENT and CHILD (in upper, lower, or mixed case).
Note that DIR, NOOP, and DONE, if used, must appear in the order shown above.
The DIR option specifies a working directory for this node, from which the Condor job will be submitted, and from which a PRE and/or POST script will be run. Note that a DAG containing DIR specifications cannot be run in conjunction with the -usedagdir command-line argument to condor_submit_dag. A rescue DAG generated by a DAG run with the -usedagdir argument will contain DIR specifications, so the -usedagdir argument is automatically disregarded when running a rescue DAG.
The optional NOOP keyword identifies that the Condor job within the node is not to be submitted to Condor. This optimization is useful in cases such as debugging a complex DAG structure, where some of the individual jobs are long-running. For this debugging of structure, some jobs are marked as NOOPs, and the DAG is initially run to verify that the control flow through the DAG is correct. The NOOP keywords are then removed before submitting the DAG. Any PRE and POST scripts for jobs specified with NOOP are executed; to avoid running the PRE and POST scripts, comment them out. The job that is not submitted to Condor is given a return value that indicates success, such that the node may also succeed. Return values of any PRE and POST scripts may still cause the node to fail. Even though the job specified with NOOP is not submitted, its submit description file must exist; the log file for the job is used, because DAGMan generates dummy submission and termination events for the job.
The optional DONE keyword identifies a node as being already completed. This is mainly used by rescue DAGs generated by DAGMan itself, in the event of a failure to complete the workflow. Nodes with the DONE keyword are not executed when the rescue DAG is run, allowing the workflow to pick up from the previous endpoint. Users should generally not use the DONE keyword. The NOOP keyword is more flexible in avoiding the execution of a job within a node. Note that, for any node marked DONE in a DAG, all of its parents must also be marked DONE; otherwise, a fatal error will result. The DONE keyword applies to the entire node. A node marked with DONE will not have a PRE or POST script run, and the Condor job will not be submitted.
The DATA key word specifies a job to be managed by the Stork data placement server. Stork software is provided by the Stork project. Please refer to their website: http://www.cct.lsu.edu/~kosar/stork/index.php.
The syntax used for each DATA entry is
DATA JobName SubmitDescriptionFileName [DIR directory] [NOOP] [DONE]
A DATA entry maps a JobName to a Stork submit description file. In all other respects, the DATA key word is identical to the JOB key word.
The keywords DIR, NOOP and DONE follow the same rules and restrictions, and they have the same effect for DATA nodes as they do for JOB nodes.
Here is an example of a simple DAG that stages in data using Stork, processes the data using Condor, and stages the processed data out using Stork. Depending upon the implementation, multiple data jobs to stage in data or to stage out data may be run in parallel.
DATA STAGE_IN1 stage_in1.stork
DATA STAGE_IN2 stage_in2.stork
JOB PROCESS process.condor
DATA STAGE_OUT1 stage_out1.stork
DATA STAGE_OUT2 stage_out2.stork
PARENT STAGE_IN1 STAGE_IN2 CHILD PROCESS
PARENT PROCESS CHILD STAGE_OUT1 STAGE_OUT2
The SCRIPT key word specifies processing that is done either before a job within the DAG is submitted to Condor or Stork for execution or after a job within the DAG completes its execution. Processing done before a job is submitted to Condor or Stork is called a PRE script. Processing done after a job completes its execution under Condor or Stork is called a POST script. A node in the DAG is comprised of the job together with PRE and/or POST scripts.
PRE and POST script lines within the DAG input file use the syntax:
SCRIPT PRE JobName ExecutableName [arguments]
SCRIPT POST JobName ExecutableName [arguments]
The SCRIPT key word identifies the type of line within the DAG input file. The PRE or POST key word specifies the relative timing of when the script is to be run. The JobName specifies the node to which the script is attached. The ExecutableName specifies the script to be executed, and it may be followed by any command line arguments to that script. The ExecutableName and optional arguments are case sensitive; they have their case preserved. Note that neither the ExecutableName nor the individual arguments within the arguments string can contain spaces.
Scripts are optional for each job, and any scripts are executed on the machine from which the DAG is submitted; this is not necessarily the same machine upon which the node's Condor or Stork job is run. Further, a single cluster of Condor jobs may be spread across several machines.
A PRE script is commonly used to place files in a staging area for the cluster of jobs to use. A POST script is commonly used to clean up or remove files once the cluster of jobs is finished running. An example uses PRE and POST scripts to stage files that are stored on tape. The PRE script reads compressed input files from the tape drive, and it uncompresses them, placing the input files in the current directory. The cluster of Condor jobs reads these input files and produces output files. The POST script compresses the output files, writes them out to the tape, and then removes both the staged input files and the output files.
DAGMan takes note of the exit value of the scripts as well as the job or jobs within the cluster. A script with an exit value not equal to 0 fails. If the PRE script fails, then the job does not run, but the POST script does run. The exit value of the POST script determines the success of the job. If this behavior is not desired, the configuration variable DAGMAN_ALWAYS_RUN_POST should be set to False; then condor_dagman will not run the POST script if the PRE script fails--the node will instead simply fail, with neither the job nor the POST script being executed. If the PRE script succeeds, the Condor or Stork job is submitted. If the job or any one of the jobs within the single cluster fails and there is no POST script, the DAG node is marked as failed. An exit value not equal to 0 indicates program failure, except as indicated by the PRE_SKIP command: if a PRE script exits with the PRE_SKIP value, then the node succeeds and the job and the POST script are both skipped. It is therefore important that a successful program return the exit value 0. It is good practice to always explicitly specify a return value in the PRE script, returning 0 in the case of success. Otherwise, the return code of the last completed process is returned, which can lead to unexpected results.
If the job fails and there is a POST script, node failure is determined by the exit value of the POST script. A failing value from the POST script marks the node as failed. A succeeding value from the POST script (even with a failed job) marks the node as successful. Therefore, the POST script may need to consider the return value from the job.
By default, the POST script is run regardless of the job's return value. As for the PRE script, it is recommended to specify return values explicitly in the POST script. Otherwise the return code of the last completed process is returned, which can lead to unexpected results.
A node not marked as failed at any point is successful.
Table 2.1
summarizes the success or failure of an entire node
for all possibilities.
An S stands for success,
an F stands for failure,
and the dash character (-) identifies that there is no script. The
asterisk (![]() ) indicates that the POST script is run, unless
DAGMAN_ALWAYS_RUN_POST is False, in which case the node
will simply fail, as described above.
) indicates that the POST script is run, unless
DAGMAN_ALWAYS_RUN_POST is False, in which case the node
will simply fail, as described above.
|
The behavior of DAGMan with respect to node success or failure can be changed with the addition of a PRE_SKIP command. A PRE_SKIP line within the DAG input file uses the syntax:
PRE_SKIP JobName non-zero-exit-code
A DAG input file with this command uses the exit value from the PRE script of the node specified by JobName. If the PRE script terminates with the exit code non-zero-exit-code, then the remainder of the node is skipped entirely. Both the job associated with the node and any POST script will not be executed, and the node will be marked as successful.
Eight variables ($JOB, $JOBID, $RETRY, $MAX_RETRIES, $RETURN, $PRE_SCRIPT_RETURN, $DAG_STATUS and $FAILED_COUNT) can be used within the DAG input file as arguments passed to a PRE or POST script.
The variable $JOB evaluates to the (case sensitive) string defined for JobName.
The variable $RETRY evaluates to an integer value set to 0 the first time a node is run, and is incremented each time the node is retried. See section 2.10.7 for the description of how to cause nodes to be retried.
The variable $MAX_RETRIES evaluates to an integer value set to the maximum number of retries for the node. See section 2.10.7 for the description of how to cause nodes to be retried. If no retries are set for the node, $MAX_RETRIES will be set to 0.
For use as an argument to POST scripts only, the variable $JOBID evaluates to a representation of the Condor job ID of the node job. It is the value of the job ClassAd attribute ClusterId, followed by a period, and then followed by the value of the job ClassAd attribute ProcId. An example of a job ID might be 1234.0. For nodes with multiple jobs in the same cluster, the ProcId value is the one of the last job within the cluster.
For use as an argument to POST scripts only, the $RETURN variable evaluates to the return value of the Condor or Stork job, if there is a single job within a cluster. With multiple jobs within the same cluster, there are two cases to consider. In the first case, all jobs within the cluster are successful; the value of $RETURN will be 0, indicating success. In the second case, one or more jobs from the cluster fail. When condor_dagman sees the first terminated event for a job that failed, it assigns that job's return value as the value of $RETURN, and attempts to remove all remaining jobs within the cluster. Therefore, if multiple jobs in the cluster fail with different exit codes, a race condition determines which exit code gets assigned to $RETURN.
A job that dies due to a signal is reported with a $RETURN value representing the additive inverse of the signal number. For example, SIGKILL (signal 9) is reported as -9. A job whose batch system submission fails is reported as -1001. A job that is externally removed from the batch system queue (by something other than condor_dagman) is reported as -1002.
For use as an argument to POST scripts only, the $PRE_SCRIPT_RETURN variable evaluates to the return value of the PRE script of a node, if there is one. If there is no PRE script, this value will be -1. If the node job was skipped because of failure of the PRE script, the value of $RETURN will be -1004 and the value of $PRE_SCRIPT_RETURN will be the exit value of the PRE script; the POST script can use this to see if the PRE script exited with an error condition, and assign success or failure to the node, as appropriate.
$DAG_STATUS and $FAILED_COUNT are documented in section 2.10.7 below.
As an example, consider the diamond-shaped DAG example. Suppose the PRE script expands a compressed file needed as input to nodes B and C. The file is named of the form JobName.gz. The DAG input file becomes
# File name: diamond.dag
#
JOB A A.condor
JOB B B.condor
JOB C C.condor
JOB D D.condor
SCRIPT PRE B pre.csh $JOB .gz
SCRIPT PRE C pre.csh $JOB .gz
PARENT A CHILD B C
PARENT B C CHILD D
The script pre.csh uses the arguments to form the file name of the compressed file:
#!/bin/csh
gunzip $argv[1]$argv[2]
The PARENT and CHILD key words specify the dependencies within the DAG. Nodes are parents and/or children within the DAG. A parent node must be completed successfully before any of its children may be started. A child node may only be started once all its parents have successfully completed.
The syntax of a dependency line within the DAG input file:
PARENT ParentJobName... CHILD ChildJobName...
The PARENT key word is followed by one or more ParentJobNames. The CHILD key word is followed by one or more ChildJobNames. Each child job depends on every parent job within the line. A single line in the input file can specify the dependencies from one or more parents to one or more children. As an example, the line
PARENT p1 p2 CHILD c1 c2produces four dependencies:
p1 to c1
p1 to c2
p2 to c1
p2 to c2
Each node in a DAG may use a unique submit description file. One key limitation is that each Condor submit description file must submit jobs described by a single cluster number. At the present time DAGMan cannot deal with a submit file producing multiple job clusters.
DAGMan enforces the dependencies within a DAG using the events recorded in the log file(s) produced by job submission to Condor. At one time, DAGMan required that all jobs within all nodes specify the same, single log file. This is no longer the case. However, if the DAG utilizes a large number of separate log files, performance may suffer. Therefore, it is better to have fewer, or even only a single log file. Unfortunately, each Stork job currently requires a separate log file.
As of Condor version 7.3.2, DAGMan's handling of log files significantly changed to improve resource usage and efficiency. Prior to Condor version 7.3.2, DAGMan assembled a list of all relevant log files at start up, by looking at all of the submit description files for all of the nodes. It kept the log files open for the duration of the DAG. Beginning with Condor version 7.3.2, DAGMan delays opening and using the submit description file until just before it is going to submit the job. At that point, DAGMan reads the submit description file to discover the job's log file. And, DAGMan monitors only the log files that are relevant to the jobs currently queued, or associated with nodes for which a POST script is running.
The advantages of the new "lazy log file evaluation" scheme are:
There is one known disadvantage of the lazy log file evaluation scheme:
Another new feature in Condor version 7.3.2 was the use of default node job user logs. Previously, it was a fatal error if the submit description file for a node job did not specify a log file. Starting with Condor version 7.3.2, DAGMan specifies a default user log file for any job that does not specify a log file. The file used as the default node log is controlled by the DAGMAN_DEFAULT_NODE_LOG configuration variable. A complete description is at section 3.3.25. Nodes specifying a log file and other nodes using the default log file can be mixed in a single DAG.
Log files for node jobs should not be placed on NFS. NFS file locking is not reliable, occasionally resulting in simultaneous acquisition of locks on a single log file by both the condor_schedd daemon and the condor_dagman job. Partially written events by the condor_schedd cause errors for condor_dagman.
An additional restriction applies to the submit description file command Log specific to a Condor job within a DAG node. This command may not be defined in such a way that it uses macros. Using a macro would violate the restriction that there be exactly one log file specified for the potentially multiple jobs within a single cluster.
Here is a modified version of the DAG input file for the diamond-shaped DAG. The modification has each node use the same submit description file.
# File name: diamond.dag
#
JOB A diamond_job.condor
JOB B diamond_job.condor
JOB C diamond_job.condor
JOB D diamond_job.condor
PARENT A CHILD B C
PARENT B C CHILD D
Here is the single Condor submit description file for this DAG:
# File name: diamond_job.condor
#
executable = /path/diamond.exe
output = diamond.out.$(cluster)
error = diamond.err.$(cluster)
log = diamond_condor.log
universe = vanilla
notification = NEVER
queue
This example uses the same Condor submit description file for all the jobs in the DAG. This implies that each node within the DAG runs the same job. The $(cluster) macro produces unique file names for each job's output. As the Condor job within each node causes a separate job submission, each has a unique cluster number.
Notification is set to NEVER in this example.
This tells Condor not to send e-mail about the completion of a job
submitted to Condor.
For DAGs with many nodes, this
reduces or eliminates excessive numbers of e-mails.
The job ClassAd attribute DAGParentNodeNames is also available for use within the submit description file. It defines a comma separated list of each JobName which is a parent node of this job's node. This attribute may be used in the arguments command for all but scheduler universe jobs. For example, if the job has two parents, with JobNames B and C, the submit description file command
arguments = $$([DAGParentNodeNames])will pass the string "B,C" as the command line argument when invoking the job.
A DAG is submitted using the program condor_submit_dag.
See the manual
page ![[*]](crossref.png) for complete details.
A simple submission has the syntax
for complete details.
A simple submission has the syntax
condor_submit_dag DAGInputFileName
The diamond-shaped DAG example may be submitted with
condor_submit_dag diamond.dagIn order to guarantee recoverability, the DAGMan program itself is run as a Condor job. As such, it needs a submit description file. condor_submit_dag produces this needed submit description file, naming it by appending .condor.sub to the DAGInputFileName. This submit description file may be edited if the DAG is submitted with
condor_submit_dag -no_submit diamond.dagcausing condor_submit_dag to generate the submit description file, but not submit DAGMan to Condor. To submit the DAG, once the submit description file is edited, use
condor_submit diamond.dag.condor.sub
An optional argument to condor_submit_dag, -maxjobs, is used to specify the maximum number of batch jobs that DAGMan may submit at one time. It is commonly used when there is a limited amount of input file staging capacity. As a specific example, consider a case where each job will require 4 Mbytes of input files, and the jobs will run in a directory with a volume of 100 Mbytes of free space. Using the argument -maxjobs 25 guarantees that a maximum of 25 jobs, using a maximum of 100 Mbytes of space, will be submitted to Condor and/or Stork at one time.
While the -maxjobs argument is used to limit the number of batch system jobs submitted at one time, it may be desirable to limit the number of scripts running at one time. The optional -maxpre argument limits the number of PRE scripts that may be running at one time, while the optional -maxpost argument limits the number of POST scripts that may be running at one time.
An optional argument to condor_submit_dag, -maxidle, is used to limit the number of idle jobs within a given DAG. When the number of idle node jobs in the DAG reaches the specified value, condor_dagman will stop submitting jobs, even if there are ready nodes in the DAG. Once some of the idle jobs start to run, condor_dagman will resume submitting jobs. Note that this parameter only limits the number of idle jobs submitted by a given instance of condor_dagman. Idle jobs submitted by other sources (including other condor_dagman runs) are ignored.
After submission, the progress of the DAG can be monitored by looking at the log file(s), observing the e-mail that job submission to Condor causes, or by using condor_q -dag. There is a large amount of information in an extra file. The name of this extra file is produced by appending .dagman.out to DAGInputFileName; for example, if the DAG file is diamond.dag, this extra file is diamond.dag.dagman.out. If this extra file grows too large, limit its size with the MAX_DAGMAN_LOG configuration macro (see section 3.3.4).
If you have some kind of problem in your DAGMan run, please save the corresponding dagman.out file; it is the most important debugging tool for DAGMan. As of version 6.8.2, the dagman.out is appended to, rather than overwritten, with each new DAGMan run.
condor_submit_dag attempts to check the DAG input file. If a problem is detected, condor_submit_dag prints out an error message and aborts.
To remove an entire DAG, consisting of DAGMan plus any jobs submitted to Condor or Stork, remove the DAGMan job running under Condor. condor_q will list the job number. Use the job number to remove the job, for example
% condor_q
-- Submitter: turunmaa.cs.wisc.edu : <128.105.175.125:36165> : turunmaa.cs.wisc.edu
ID OWNER SUBMITTED RUN_TIME ST PRI SIZE CMD
9.0 smoler 10/12 11:47 0+00:01:32 R 0 8.7 condor_dagman -f -
11.0 smoler 10/12 11:48 0+00:00:00 I 0 3.6 B.out
12.0 smoler 10/12 11:48 0+00:00:00 I 0 3.6 C.out
3 jobs; 2 idle, 1 running, 0 held
% condor_rm 9.0
Before the DAGMan job stops running, it uses condor_rm to remove any jobs within the DAG that are running.
In the case where a machine is scheduled to go down, DAGMan will clean up memory and exit. However, it will leave any submitted jobs in Condor's queue.
It may be desired to temporarily suspend a running DAG. For example, the load may be high on the submit machine, and therefore it is desired to prevent DAGMan from submitting any more jobs until the load goes down. There are two ways to suspend (and resume) a running DAG.
After placing the condor_dagman job on hold, no new node jobs will be submitted, and no PRE or POST scripts will be run. Any node jobs already in the Condor queue will continue undisturbed. If the condor_dagman job is left on hold, it will remain in the Condor queue after all of the currently running node jobs are finished. To resume the DAG, use condor_release on the condor_dagman job.
Note that while the condor_dagman job is on hold, no updates will be made to the dagman.out file.
The second way of suspending a DAG uses the existence of a specially-named file to change the state of the DAG. When in this halted state, no PRE scripts will be run, and no node jobs will be submitted. Running node jobs will continue undisturbed. A halted DAG will still run POST scripts, and it will still update the dagman.out file. This differs from behavior of a DAG that is held. Furthermore, a halted DAG will not remain in the queue indefinitely; when all of the running node jobs have finished, DAGMan will create a Rescue DAG and exit.
To resume a halted DAG, remove the halt file.
The specially-named file must be placed in the same directory as the DAG input file. The naming is the same as the DAG input file concatenated with the string .halt. For example, if the DAG input file is test1.dag, then test1.dag.halt will be the required name of the halt file.
As any DAG is first submitted with condor_submit_dag, a check is made for a halt file. If one exists, it is removed.
The RETRY key word provides a way to retry failed nodes. The use of retry is optional. The syntax for retry is
RETRY JobName NumberOfRetries [UNLESS-EXIT value]
where JobName identifies the node. NumberOfRetries is an integer number of times to retry the node after failure. The implied number of retries for any node is 0, the same as not having a retry line in the file. Retry is implemented on nodes, not parts of a node.
The diamond-shaped DAG example may be modified to retry node C:
# File name: diamond.dag
#
JOB A A.condor
JOB B B.condor
JOB C C.condor
JOB D D.condor
PARENT A CHILD B C
PARENT B C CHILD D
Retry C 3
If node C is marked as failed (for any reason), then it is started over as a first retry. The node will be tried a second and third time, if it continues to fail. If the node is marked as successful, then further retries do not occur.
Retry of a node may be short circuited using the optional key word UNLESS-EXIT (followed by an integer exit value). If the node exits with the specified integer exit value, then no further processing will be done on the node.
The variable $RETRY evaluates to an integer value set to 0 first time a node is run, and is incremented each time for each time the node is retried. The variable $MAX_RETRIES is the value set for NumberOfRetries.
The ABORT-DAG-ON key word provides a way to abort the entire DAG if a given node returns a specific exit code. The syntax for ABORT-DAG-ON is
ABORT-DAG-ON JobName AbortExitValue [RETURN DAGReturnValue]
If the node specified by JobName returns the specified AbortExitValue, the DAG is immediately aborted. A DAG abort differs from a node failure, in that a DAG abort causes all nodes within the DAG to be stopped immediately. This includes removing the jobs in nodes that are currently running. A node failure allows the DAG to continue running, until no more progress can be made due to dependencies.
An abort overrides node retries. If a node returns the abort exit value, the DAG is aborted, even if the node has retry specified.
When a DAG aborts, by default it exits with the node return value that caused the abort. This can be changed by using the optional RETURN key word along with specifying the desired DAGReturnValue. The DAG abort return value can be used for DAGs within DAGs, allowing an inner DAG to cause an abort of an outer DAG.
Adding ABORT-DAG-ON for node C in the diamond-shaped DAG
# File name: diamond.dag
#
JOB A A.condor
JOB B B.condor
JOB C C.condor
JOB D D.condor
PARENT A CHILD B C
PARENT B C CHILD D
Retry C 3
ABORT-DAG-ON C 10 RETURN 1
causes the DAG to be aborted, if node C exits with a return value of 10. Any other currently running nodes (only node B is a possibility for this particular example) are stopped and removed. If this abort occurs, the return value for the DAG is 1.
The VARS key word provides a method for defining a macro that can be referenced in the node's submit description file. These macros are defined on a per-node basis, using the following syntax:
VARS JobName macroname="string" [macroname="string"... ]
The macro may be used within the submit description file of the relevant node. A macroname consists of alphanumeric characters (a..Z and 0..9), as well as the underscore character. The space character delimits macros, when there is more than one macro defined for a node on a single line. Multiple lines defining macros for the same node are permitted.
Correct syntax requires that the string must be
enclosed in double quotes.
To use a double quote inside string,
escape it with the backslash character (\).
To add the backslash character itself, use two backslashes (\\).
The string $(JOB) maybe used in string and will expand to
JobName.
If the VARS line appears in a DAG file used as a splice file,
then $(JOB) will be the fully scoped name of the node.
Note that the macroname itself cannot begin with the string queue, in any combination of upper or lower case.
If the DAG input file contains
# File name: diamond.dag
#
JOB A A.condor
JOB B B.condor
JOB C C.condor
JOB D D.condor
VARS A state="Wisconsin"
PARENT A CHILD B C
PARENT B C CHILD D
then file A.condor may use the macro state.
This example submit description file for the Condor
job in node A passes the value
of the macro as a command-line argument to the job.
# file name: A.condor
executable = A.exe
log = A.log
error = A.err
arguments = "$(state)"
queue
This Condor job's command line will be
A.exe WisconsinThe use of macros may allow a reduction in the necessary number of unique submit description files.
A separate example shows an intended use of a VARS entry in the DAG input file. This use may dramatically reduce the number of Condor submit description files needed for a DAG. In the case where the submit description file for each node varies only in file naming, the use of a substitution macro within the submit description file reduces the need to a single submit description file. Note that the user log file for a job currently cannot be specified using a macro passed from the DAG.
The example uses a single submit description file in the DAG input file, and uses the VARS entry to name output files.
The relevant portion of the DAG input file appears as
JOB A theonefile.sub
JOB B theonefile.sub
JOB C theonefile.sub
VARS A outfilename="A"
VARS B outfilename="B"
VARS C outfilename="C"
The submit description file appears as
# submit description file called: theonefile.sub
executable = progX
universe = standard
output = $(outfilename)
error = error.$(outfilename)
log = progX.log
queue
For a DAG such as this one, but with thousands of nodes, being able to write and maintain a single submit description file and a single, yet more complex, DAG input file is preferable.
If a VARS macroname for a specific node in a DAG input file is defined more than once, as it would be with the partial file contents
JOB job1 job.condor VARS job1 a="foo" VARS job1 a="bar"a warning is written to the log, of the format
Warning: VAR <macroname> is already defined in job <JobName> Discovered at file "<DAG input file name>", line <line number>
The behavior of DAGMan is such that all definitions for the macroname exist, but only the last one defined is used as the variable's value. For example, if the example is within the DAG input file, and the job's submit description file utilized the value with
arguments = "$(a)"then the argument will be bar.
The value of a VARS macroname may contain spaces and tabs. It is also possible to have double quote marks and backslashes within these values. Unfortunately, it is not possible to have single quote marks within these values. In order to have spaces or tabs within a value, use the new syntax format for the arguments command in the node's Condor job submit description file, as described in section 10. Double quote marks are escaped differently, depending on the new syntax or old syntax argument format. Note that in both syntaxes, double quote marks require two levels of escaping: one level is for the parsing of the DAG input file, and the other level is for passing the resulting value through condor_submit.
As an example, here are only the relevant parts of a DAG input file. Note that the NodeA value for second contains a tab.
Vars NodeA first="Alberto Contador"
Vars NodeA second="\"\"Andy Schleck\"\""
Vars NodeA third="Lance\\ Armstrong"
Vars NodeA misc="!@#$%^&*()_-=+=[]{}?/"
Vars NodeB first="Lance_Armstrong"
Vars NodeB second="\\\"Andreas_Kloden\\\""
Vars NodeB third="Ivan\\_Basso"
Vars NodeB misc="!@#$%^&*()_-=+=[]{}?/"
The new syntax arguments line of the Condor submit description file for NodeA is
arguments = "'$(first)' '$(second)' '$(third)' '$(misc)'"The single quotes around each variable reference are only necessary if the variable value may contain spaces or tabs. The resulting values passed to the NodeA executable are
Alberto Contador
"Andy Schleck"
Lance\ Armstrong
!@#$%^&*()_-=+=[]{}?/
The old syntax arguments line of the Condor submit description file for NodeB is
arguments = $(first) $(second) $(third) $(misc)
The resulting values passed to the NodeB executable are
Lance_Armstrong
"Andreas_Kloden"
Ivan\_Basso
!@#$%^&*()_-=+=[]{}?/
The PRIORITY key word assigns a priority to a DAG node. The syntax for PRIORITY is
PRIORITY JobName PriorityValue
The node priority affects the order in which nodes that are ready at the same time will be submitted. Note that node priority does not override the DAG dependencies.
Node priority is mainly relevant if node submission is throttled via the -maxjobs or -maxidle command-line arguments or the DAGMAN_MAX_JOBS_SUBMITTED or DAGMAN_MAX_JOBS_IDLE configuration variables. Note that PRE scripts can affect the order in which jobs run, so DAGs containing PRE scripts may not run the nodes in exact priority order, even if doing so would satisfy the DAG dependencies.
The priority value is an integer (which can be negative). A larger numerical priority is better (will be run before a smaller numerical value). The default priority is 0.
Adding PRIORITY for node C in the diamond-shaped DAG
# File name: diamond.dag
#
JOB A A.condor
JOB B B.condor
JOB C C.condor
JOB D D.condor
PARENT A CHILD B C
PARENT B C CHILD D
Retry C 3
PRIORITY C 1
This will cause node C to be submitted before node B. Without this priority setting for node C, node B would be submitted first.
Priorities are propagated to children, to SUBDAGs, and to the Condor job itself, via the JobPrio attribute in the job's ClassAd. The priority is defined to be the maximum of the DAG PRIORITY directive for the job itself and the PRIORITYs of all its parents. Here is an example to clarify:
# File name: priorities.dag
#
JOB A A.condor
JOB B B.condor
JOB C C.condor
SUBDAG EXTERNAL D SD.subdag
PARENT A C CHILD B
PARENT C CHILD D
PRIORITY A 60
PRIORITY B 0
PRIORITY C 5
PRIORITY D 100
In this example, node B is a child of nodes A and C. Node B's priority is initially set to 0, but its priority becomes 60, because that is the maximum of its initial priority of 0, and the priorities of its parents A with priority 60 and C with priority 5. Node D has only parent node C. Since the priority of node D will become at least as big as that of its parent node C, node D is assigned a priority of 100. And, all nodes in the D SUBDAG will have priority at least 100. This priority is assigned by DAGMan. There is no way to change the priority in the submit description file for a job, as DAGMan will override any priority command placed in a submit description file. The implication of this priority propagation is that for DAGs with a large number of edges (representing dependencies), the priorities of child nodes far from the root nodes will tend to be the same. The priorities of the leaf nodes of a tree-shaped DAG, or of DAGs with a relatively small number of dependencies, will not tend to be the same.
In order to limit the number of submitted job clusters within a DAG, the nodes may be placed into categories by assignment of a name. Then, a maximum number of submitted clusters may be specified for each category.
The CATEGORY key word assigns a category name to a DAG node. The syntax for CATEGORY is
CATEGORY JobName CategoryName
Category names cannot contain white space.
The MAXJOBS key word limits the number of submitted job clusters on a per category basis. The syntax for MAXJOBS is
MAXJOBS CategoryName MaxJobsValue
If the number of submitted job clusters for a given category reaches the limit, no further job clusters in that category will be submitted until other job clusters within the category terminate. If MAXJOBS is not set for a defined category, then there is no limit placed on the number of submissions within that category.
Note that a single invocation of condor_submit results in one job cluster. The number of Condor jobs within a cluster may be greater than 1.
The configuration variable DAGMAN_MAX_JOBS_SUBMITTED and the condor_submit_dag -maxjobs command-line option are still enforced if these CATEGORY and MAXJOBS throttles are used.
Please see the end of section 2.10.7 on DAG Splicing for a description of the interaction between categories and splices.
The CONFIG keyword specifies a configuration file to be used to set configuration variables related to condor_dagman when running this DAG. The syntax for CONFIG is
CONFIG ConfigFileName
If the DAG file contains a line like this,
CONFIG dagman.config
then the configuration values in the file dagman.config will be used
for this DAG.
Configuration macros for condor_dagman can be specified in several ways, as given within the ordered list:
_CONDOR_ to the configuration variable's name.
In the above list, configuration values specified later in the list override ones specified earlier For example, a value specified on the condor_submit_dag command line overrides corresponding values in any configuration file. And, a value specified in a DAGMan-specific configuration file overrides values specified in a general Condor configuration file.
Configuration variables that are not for condor_dagman and not utilized by DaemonCore, yet are specified in a condor_dagman-specific configuration file are ignored.
Only a single configuration file can be specified for a given condor_dagman run. For example, if one file is specified within a DAG input file, and a different file is specified on the condor_submit_dag command line, this is a fatal error at submit time. The same is true if different configuration files are specified in multiple DAG input files, and referenced in a single condor_submit_dag command.
If multiple DAGs are run in a single condor_dagman run, the configuration options specified in the condor_dagman configuration file, if any, apply to all DAGs, even if some of the DAGs specify no configuration file.
Configuration variables relating to DAGMan may be found in section 3.3.25.
condor_dagman works by watching log files for events, such as submission, termination, and going on hold. When a new job is ready to be run, it is submitted to the condor_schedd, which needs to acquire a computing resource. Acquisition requires the condor_schedd to contact the central manager and get a claim on a machine, and this claim cycle can take many minutes.
Configuration variable DAGMAN_HOLD_CLAIM_TIME avoids the wait for a negotiation cycle. When set to a non zero value, the condor_schedd keeps a claim idle, such that the condor_startd delays in shifting from the Claimed to the Preempting state (see Figure 3.2). Thus, if another job appears that is suitable for the claimed resource, then the condor_schedd will submit the job directly to the condor_startd, avoiding the wait and overhead of a negotiation cycle. This results in a speed up of job completion, especially for linear DAGs in pools that have lengthy negotiation cycle times.
By default, DAGMAN_HOLD_CLAIM_TIME is 20, causing a claim to remain idle for 20 seconds, during which time a new job can be submitted directly to the already-claimed condor_startd. A value of 0 means that claims are not held idle for a running DAG. If a DAG node has no children, the value of DAGMAN_HOLD_CLAIM_TIME will be ignored; the KeepClaimIdle attribute will not be defined in the job ClassAd of the node job, unless the job requests it using the submit command keep_claim_idle.
A single use of condor_submit_dag may execute multiple, independent DAGs. Each independent DAG has its own DAG input file. These DAG input files are command-line arguments to condor_submit_dag (see the condor_submit_dag manual page at 10).
Internally, all of the independent DAGs are combined into a single, larger DAG, with no dependencies between the original independent DAGs. As a result, any generated rescue DAG file represents all of the input DAGs as a single DAG. The file name of this rescue DAG is based on the DAG input file listed first within the command-line arguments to condor_submit_dag (unlike a single-DAG rescue DAG file, however, the file name will be <whatever>.dag_multi.rescue or <whatever>.dag_multi.rescueNNN, as opposed to just <whatever>.dag.rescue or <whatever>.dag.rescueNNN). Other files such as dagman.out and the lock file also have names based on this first DAG input file.
The success or failure of the independent DAGs is well defined. When multiple, independent DAGs are submitted with a single command, the success of the composite DAG is defined as the logical AND of the success of each independent DAG. This implies that failure is defined as the logical OR of the failure of any of the independent DAGs.
By default, DAGMan internally renames the nodes to avoid node name collisions. If all node names are unique, the renaming of nodes may be disabled by setting the configuration variable DAGMAN_MUNGE_NODE_NAMES to False (see 3.3.25).
The organization and dependencies of the jobs within a DAG are the keys to its utility. Some DAGs are naturally constructed hierarchically, such that a node within a DAG is also a DAG. Condor DAGMan handles this situation easily. DAGs can be nested to any depth.
One of the highlights of using the SUBDAG feature is that portions of a DAG may be constructed and modified during the execution of the DAG. A drawback may be that each SUBDAG causes its own distinct job submission of condor_dagman, leading to a larger number of jobs, together with their potential need of carefully constructed policy configuration to throttle node submission or execution.
Since more than one DAG is being discussed, here is terminology introduced to clarify which DAG is which. Reuse the example diamond-shaped DAG as given in Figure 2.2. Assume that node B of this diamond-shaped DAG will itself be a DAG. The DAG of node B is called a SUBDAG, inner DAG, or lower-level DAG. The diamond-shaped DAG is called the outer or top-level DAG.
Work on the inner DAG first. Here is a very simple linear DAG input file used as an example of the inner DAG.
# File name: inner.dag
#
JOB X X.submit
JOB Y Y.submit
JOB Z Z.submit
PARENT X CHILD Y
PARENT Y CHILD Z
The Condor submit description file, used by condor_dagman, corresponding to inner.dag will be named inner.dag.condor.sub. The DAGMan submit description file is always named <DAG file name>.condor.sub. Each DAG or SUBDAG results in the submission of condor_dagman as a Condor job, and condor_submit_dag creates this submit description file.
The preferred presentation of the DAG input file for the outer DAG is
# File name: diamond.dag
#
JOB A A.submit
SUBDAG EXTERNAL B inner.dag
JOB C C.submit
JOB D D.submit
PARENT A CHILD B C
PARENT B C CHILD D
The preferred presentation is equivalent to
# File name: diamond.dag
#
JOB A A.submit
JOB B inner.dag.condor.sub
JOB C C.submit
JOB D D.submit
PARENT A CHILD B C
PARENT B C CHILD D
Within the outer DAG's input file, the SUBDAG keyword specifies a special case of a JOB node, where the job is itself a DAG.
The syntax for each SUBDAG entry is
SUBDAG EXTERNAL JobName DagFileName [DIR directory] [NOOP] [DONE]
The optional specifications of DIR, NOOP, and DONE, if used, must appear in this order within the entry.
A SUBDAG node is essentially the same as any other node, except that the DAG input file for the inner DAG is specified, instead of the Condor submit file. The keyword EXTERNAL means that the SUBDAG is run within its own instance of condor_dagman.
NOOP and DONE for SUBDAG nodes have the same effect that they do for JOB nodes.
Here are details that affect SUBDAGs:
There are three ways to generate the <DAG file name>.condor.sub file of a SUBDAG:
When the <DAG file name>.condor.sub file is generated lazily, this file is generated immediately before the SUBDAG job is submitted. Generation is accomplished by running
condor_submit_dag -no_submiton the DAG input file specified in the SUBDAG entry. This is the default behavior. There are advantages to this lazy mode of submit description file creation for the SUBDAG:
The main disadvantage of lazy submit file generation is that a syntax error in the DAG input file of a SUBDAG will not be discovered until the outer DAG tries to run the inner DAG.
When <DAG file name>.condor.sub files are generated eagerly, condor_submit_dag runs itself recursively (with the -no_submit option) on each SUBDAG, so all of the <DAG file name>.condor.sub files are generated before the top-level DAG is actually submitted. To generate the <DAG file name>.condor.sub files eagerly, pass the -do_recurse flag to condor_submit_dag; also set the DAGMAN_GENERATE_SUBDAG_SUBMITS configuration variable to False, so that condor_dagman does not re-run condor_submit_dag at run time thereby regenerating the submit description files.
To generate the .condor.sub files manually, run
condor_submit_dag -no_submiton each lower-level DAG file, before running condor_submit_dag on the top-level DAG file; also set the DAGMAN_GENERATE_SUBDAG_SUBMITS configuration variable to False, so that condor_dagman does not re-run condor_submit_dag at run time. The main reason for generating the <DAG file name>.condor.sub files manually is to set options for the lower-level DAG that one would not otherwise be able to set An example of this is the -insert_sub_file option. For instance, using the given example do the following to manually generate Condor submit description files:
condor_submit_dag -no_submit -insert_sub_file fragment.sub inner.dag condor_submit_dag diamond.dag
Note that most condor_submit_dag command-line flags have corresponding configuration variables, so we encourage the use of per-DAG configuration files, especially in the case of nested DAGs. This is the easiest way to set different options for different DAGs in an overall workflow.
It is possible to combine more than one method of generating the <DAG file name>.condor.sub files. For example, one might pass the -do_recurse flag to condor_submit_dag, but leave the DAGMAN_GENERATE_SUBDAG_SUBMITS configuration variable set to the default of True. Doing this would provide the benefit of an immediate error message at submit time, if there is a syntax error in one of the inner DAG input files, but the lower-level <DAG file name>.condor.sub files would still be regenerated before each nested DAG is submitted.
The values of the following command-line flags are passed from the top-level condor_submit_dag instance to any lower-level condor_submit_dag instances. This occurs whether the lower-level submit description files are generated lazily or eagerly:
The values of the following command-line flags are preserved in any already-existing lower-level DAG submit description files:
Other command-line arguments are set to their defaults in any lower-level invocations of condor_submit_dag.
The -force option will cause existing DAG submit description files to be overwritten without preserving any existing values.
The outer DAG is submitted as before, with the command
condor_submit_dag diamond.dag
When using nested DAGs, we strongly recommend that you use "new-style" rescue DAGs. This is the default. Using "new-style" rescue DAGs will automatically run the proper rescue DAG(s) if there is a failure in the work flow. For example, if one of the nodes in inner.dag fails, this will produce a rescue DAG for inner.dag (named inner.dag.rescue.001, etc.). Then, since inner.dag failed, node B of diamond.dag will fail, producing a rescue DAG for diamond.dag (named diamond.dag.rescue.001, etc.). If the command
condor_submit_dag diamond.dagis re-run, the most recent outer rescue DAG will be run, and this will re-run the inner DAG, which will in turn run the most recent inner rescue DAG. The use of "old-style" rescue DAGs will require the renaming of the inner rescue DAG or manually running it.
Remember that, unless the DIR keyword is used in the outer DAG, the inner DAG utilizes the current working directory when the outer DAG is submitted. Therefore, all paths utilized by the inner DAG file must be specified accordingly.
A weakness in scalability exists when submitting a DAG within a DAG. Each executing independent DAG requires its own invocation of condor_dagman to be running. The scaling issue presents itself when the same semantic DAG is reused hundreds or thousands of times in a larger DAG. Further, there may be many rescue DAGs created if a problem occurs. To alleviate these concerns, the DAGMan language introduces the concept of graph splicing.
A splice is a named instance of a subgraph which is specified in a
separate DAG file.
The splice is treated as a whole entity during dependency
specification in the including DAG.
The same DAG file may be reused as differently named splices,
each one
incorporating a copy of the dependency graph (and nodes therein) into the
including DAG.
Any splice in an including DAG may have dependencies
between the sets of initial and final nodes.
A splice may be incorporated into an including DAG without any
dependencies; it is considered
a disjoint DAG within the including DAG.
The nodes within a splice are scoped according to
a hierarchy of names associated with the splices,
as the splices are parsed from the top level DAG file.
The scoping character to describe the
inclusion hierarchy of nodes into the top level dag is
'+'.
This character is chosen due
to a restriction in the allowable characters which may be in a file name
across the variety of ports that Condor supports.
In any DAG file, all splices must have unique names,
but the same splice name may be reused in different DAG files.
Condor does not detect nor support splices that form a cycle within the DAG. A DAGMan job that causes a cyclic inclusion of splices will eventually exhaust available memory and crash.
The SPLICE keyword in a DAG input file creates a named instance of a DAG as specified in another file as an entity which may have PARENT and CHILD dependencies associated with other splice names or node names in the including DAG file. The syntax for SPLICE is
SPLICE SpliceName DagFileName [DIR directory]
After parsing incorporates a splice, all nodes within the spice become nodes within the including DAG.
The following series of examples illustrate potential uses of splicing. To simplify the examples, presume that each and every job uses the same, simple Condor submit description file:
# BEGIN SUBMIT FILE submit.condor executable = /bin/echo arguments = OK universe = vanilla output = $(jobname).out error = $(jobname).err log = submit.log notification = NEVER queue # END SUBMIT FILE submit.condor
This first simple example splices a diamond-shaped DAG in between the two nodes of a top level DAG. Here is the DAG input file for the diamond-shaped DAG:
# BEGIN DAG FILE diamond.dag JOB A submit.condor VARS A jobname="$(JOB)" JOB B submit.condor VARS B jobname="$(JOB)" JOB C submit.condor VARS C jobname="$(JOB)" JOB D submit.condor VARS D jobname="$(JOB)" PARENT A CHILD B C PARENT B C CHILD D # END DAG FILE diamond.dag
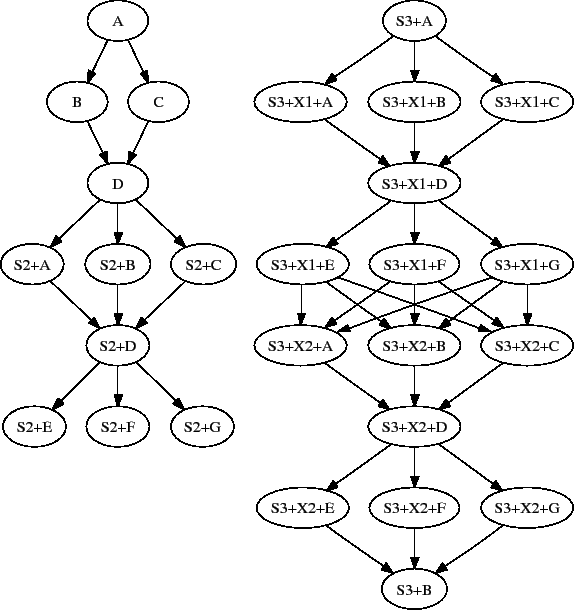
The top level DAG incorporates the diamond-shaped splice:
# BEGIN DAG FILE toplevel.dag JOB X submit.condor VARS X jobname="$(JOB)" JOB Y submit.condor VARS Y jobname="$(JOB)" # This is an instance of diamond.dag, given the symbolic name DIAMOND SPLICE DIAMOND diamond.dag # Set up a relationship between the nodes in this dag and the splice PARENT X CHILD DIAMOND PARENT DIAMOND CHILD Y # END DAG FILE toplevel.dag
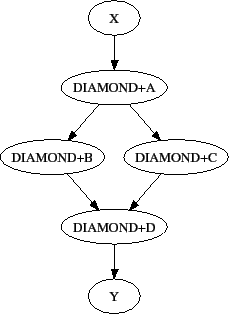
Figure 2.3 illustrates the resulting top level DAG and the dependencies produced. Notice the naming of nodes scoped with the splice name. This hierarchy of splice names assures unique names associated with all nodes.
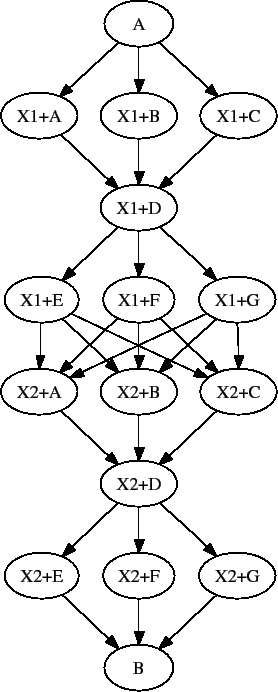
Figure 2.4 illustrates the starting point for a more complex example. The DAG input file X.dag describes this X-shaped DAG. The completed example displays more of the spatial constructs provided by splices. Pay particular attention to the notion that each named splice creates a new graph, even when the same DAG input file is specified.
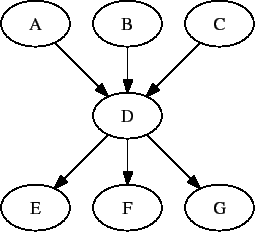
# BEGIN DAG FILE X.dag JOB A submit.condor VARS A jobname="$(JOB)" JOB B submit.condor VARS B jobname="$(JOB)" JOB C submit.condor VARS C jobname="$(JOB)" JOB D submit.condor VARS D jobname="$(JOB)" JOB E submit.condor VARS E jobname="$(JOB)" JOB F submit.condor VARS F jobname="$(JOB)" JOB G submit.condor VARS G jobname="$(JOB)" # Make an X-shaped dependency graph PARENT A B C CHILD D PARENT D CHILD E F G # END DAG FILE X.dag
File s1.dag continues the example, presenting the DAG input file that incorporates two separate splices of the X-shaped DAG. Figure 2.5 illustrates the resulting DAG.
# BEGIN DAG FILE s1.dag JOB A submit.condor VARS A jobname="$(JOB)" JOB B submit.condor VARS B jobname="$(JOB)" # name two individual splices of the X-shaped DAG SPLICE X1 X.dag SPLICE X2 X.dag # Define dependencies # A must complete before the initial nodes in X1 can start PARENT A CHILD X1 # All final nodes in X1 must finish before # the initial nodes in X2 can begin PARENT X1 CHILD X2 # All final nodes in X2 must finish before B may begin. PARENT X2 CHILD B # END DAG FILE s1.dag
The top level DAG in the hierarchy of this complex example is described by the DAG input file toplevel.dag. Figure 2.6 illustrates the final DAG. Notice that the DAG has two disjoint graphs in it as a result of splice S3 not having any dependencies associated with it in this top level DAG.
# BEGIN DAG FILE toplevel.dag JOB A submit.condor VARS A jobname="$(JOB)" JOB B submit.condor VARS B jobname="$(JOB)" JOB C submit.condor VARS C jobname="$(JOB)" JOB D submit.condor VARS D jobname="$(JOB)" # a diamond-shaped DAG PARENT A CHILD B C PARENT B C CHILD D # This splice of the X-shaped DAG can only run after # the diamond dag finishes SPLICE S2 X.dag PARENT D CHILD S2 # Since there are no dependencies for S3, # the following splice is disjoint SPLICE S3 s1.dag # END DAG FILE toplevel.dag
The DIR option specifies a working directory for a splice, from which the splice will be parsed and the containing jobs submitted. The directory associated with the splices' DIR specification will be propagated as a prefix to all nodes in the splice and any included splices. If a node already has a DIR specification, then the splice's DIR specification will be a prefix to the nodes and separated by a directory separator character. Jobs in included splices with an absolute path for their DIR specification will have their DIR specification untouched. Note that a DAG containing DIR specifications cannot be run in conjunction with the -usedagdir command-line argument to condor_submit_dag. A rescue DAG generated by a DAG run with the -usedagdir argument will contain DIR specifications, so the rescue DAG must be run without the -usedagdir argument.
Categories normally refer only to nodes within a given splice. All of the assignments of nodes to a category, and the setting of the category throttle, should be done within a single DAG file. However, it is now possible to have categories include nodes from within more than one splice. To do this, the category name is prefixed with the '+' (plus) character. This tells DAGMan that the category is a cross-splice category. Towards deeper understanding, what this really does is prevent renaming of the category when the splice is incorporated into the upper-level DAG. The MAXJOBS specification for the category can appear in either the upper-level DAG file or one of the splice DAG files. It probably makes the most sense to put it in the upper-level DAG file.
Here is an example which applies a single limitation on submitted jobs, identifying the category with +init.
# relevant portion of file name: upper.dag
SPLICE A splice1.dag
SPLICE B splice2.dag
MAXJOBS +init 2
# relevant portion of file name: splice1.dag
JOB C C.sub
CATEGORY C +init
JOB D D.sub
CATEGORY D +init
# relevant portion of file name: splice2.dag
JOB X X.sub
CATEGORY X +init
JOB Y Y.sub
CATEGORY Y +init
For both global and non-global category throttles, settings at a higher level in the DAG override settings at a lower level. In this example:
# relevant portion of file name: upper.dag
SPLICE A lower.dag
MAXJOBS A+catX 10
MAXJOBS +catY 2
# relevant portion of file name: lower.dag
MAXJOBS catX 5
MAXJOBS +catY 1
the resulting throttle settings are 2 for the +catY category and 10 for the A+catX category in splice. Note that non-global category names are prefixed with their splice name(s), so to refer to a non-global category at a higher level, the splice name must be included.
A FINAL node is a special node that is always run at the end of the DAG, even if previous nodes in the DAG have failed. Final nodes can be used for tasks such as cleaning up intermediate files and checking the output of previous nodes.
The FINAL key word specifies a job to be run at the end of the DAG. The syntax used for each FINAL entry is
FINAL JobName SubmitDescriptionFileName [DIR directory] [NOOP]
The FINAL node is identified by JobName, and the Condor job is described by the contents of the Condor submit description file given by SubmitDescriptionFileName.
The key words DIR and NOOP are not case sensitive. Note that DIR and NOOP, if used, must appear in the order shown above. See section 2.10.2 for the descriptions of these two keywords.
The only case in which a FINAL node is not run is if the configuration variable DAGMAN_STARTUP_CYCLE_DETECT is set to True, and a cycle is detected at start up time. If DAGMAN_STARTUP_CYCLE_DETECT is set to False and a cycle is detected during the course of the run, the FINAL node will be run.
One of the most important considerations with a FINAL node is that the success or failure of the FINAL node overrides all previous status in determining the success or failure of the DAG. For example, if some nodes of a DAG fail, but the FINAL node succeeds, the DAG will be considered successful. Therefore, it is important to be careful about setting the exit status of the FINAL node.
Two special macros have been introduced for use by FINAL nodes: $DAG_STATUS and $FAILED_COUNT. These macros may also be used by other nodes.
$DAG_STATUS is the status of the DAG, defined with the following values:
$FAILED_COUNT is defined by the number of nodes that have failed in the DAG.
The $DAG_STATUS and $FAILED_COUNT macros can be used both as PRE and POST script arguments, and in node job submit description files. As an example of this, here are the partial contents of the DAG input file,
FINAL final_node final_node.sub
SCRIPT PRE final_node final_pre.pl $DAG_STATUS $FAILED_COUNT
and here are the partial contents of the submit description file, final_node.sub
arguments = "$(DAG_STATUS) $(FAILED_COUNT)"
If there is a FINAL node specified for a DAG, it will be run at the end of the workflow. If this FINAL node must not do anything in certain cases, use the $DAG_STATUS and $FAILED_COUNT macros to take appropriate actions. Here is an example of that behavior. It uses a PRE script that aborts if the DAG has been removed with condor_rm, which, in turn, causes the FINAL node to be considered failed without actually submitting the Condor job specified for the node. Partial contents of the DAG input file:
FINAL final_node final_node.sub
SCRIPT PRE final_node final_pre.pl $DAG_STATUS
and partial contents of the Perl PRE script, final_pre.pl:
#! /usr/bin/env perl
if ($ARGV[0] eq 4) {
exit(1);
}
There are restrictions on usage of a FINAL node. There is no DONE option for the Condor job. And, other nodes may not reference the FINAL node in specifications of
DAGMan can help with the re-running of uncompleted portions of a DAG, when one or more nodes result in failure, or when a running DAG is removed with condor_rm. If any node in the DAG fails, the remainder of the DAG is continued until no more forward progress can be made based on the DAG's dependencies. At this point, DAGMan produces a file called a Rescue DAG. A Rescue DAG is also produced if the condor_dagman job itself is removed with condor_rm.
If the DAG is resubmitted utilizing the Rescue DAG, the successfully completed nodes will not be re-executed. As of Condor version 7.7.2, the Rescue DAG file is a partial DAG file.
A partial Rescue DAG file contains only information about which nodes are done, and the number of retries remaining for nodes with retries. It does not contain information such as the actual DAG structure and the specification of the submit file for each node job. Partial Rescue DAGs are automatically parsed in combination with the original DAG file, which contains information about the DAG structure. This updated implementation means that a change in the original DAG input file, such as specifying a different submit description file for a node job, will take effect when running the partial Rescue DAG.
The previous behavior of producing full DAG input file is implemented by setting the configuration variable DAGMAN_WRITE_PARTIAL_RESCUE to the non-default value of False.
Note that the removal of a node from the original DAG input file, together with a DONE specification in the Rescue DAG for a node that no longer exists is a warning, as opposed to an error, unless the DAGMAN_USE_STRICT configuration variable is set to a value of 1 or higher. Comment out the line with DONE in the partial Rescue DAG file to avoid a warning or error.
To run a full Rescue DAG, either one left over from an older version of DAGMan, or one produced by setting DAGMAN_WRITE_PARTIAL_RESCUE to False, directly specify the full Rescue DAG file instead of the original DAG file. For example:
condor_submit_dag my.dag.rescue002
Re-submission of the original DAG input file causes condor_dagman to try to parse the Rescue DAG file in combination with the original DAG input file, which will result in failure if the Rescue DAG is a full Rescue DAG file.
Note that if multiple DAG input files are specified on the condor_submit_dag command line, a single Rescue DAG encompassing all of the input DAGs is generated.
If the Rescue DAG file is generated before all retries of a node are completed, then the Rescue DAG file will also contain Retry entries. The number of retries will be set to the appropriate remaining number of retries. The configuration variable DAGMAN_RESET_RETRIES_UPON_RESCUE , section 3.3.25, controls whether or not node retries are reset in a Rescue DAG.
The granularity defining success or failure in the Rescue DAG is the node. For a node that fails, all parts of the node will be re-run, even if some parts were successful the first time. For example, if a node's PRE script succeeds, but then the node's Condor job cluster fails, the entire node, which includes the PRE script will be re-run. A job cluster may result in the submission of multiple Condor jobs. If one of the multiple jobs fails, the node fails. Therefore, the Rescue DAG will re-run the entire node, implying the submission of the entire cluster of jobs, not just the one(s) that failed.
Statistics about the failed DAG execution are presented as comments at the beginning of the Rescue DAG input file.
The Rescue DAG is automatically generated by condor_dagman when a node
within the DAG fails or when condor_dagman itself is removed
with condor_rm.
The file name of the Rescue DAG, and usage of the Rescue
DAG changed from explicit specification to implicit usage
beginning with Condor version 7.1.0.
Current naming of the Rescue DAG appends the string
.rescue<XXX> to the original DAG input file name.
Values for <XXX> start at 001 and continue
to 002, 003, and beyond.
If a Rescue DAG exists,
the Rescue DAG with the largest magnitude value for <XXX>
will be used, and its usage is implied.
Here is an example showing file naming and DAG submission for the case of a failed DAG. The initial DAG is submitted with
condor_submit_dag my.dagA failure of this DAG results in the Rescue DAG named my.dag.rescue001. The DAG is resubmitted using the same command:
condor_submit_dag my.dagThis resubmission of the DAG uses the Rescue DAG file my.dag.rescue001, because it exists. Failure of this Rescue DAG results in another Rescue DAG called my.dag.rescue002. If the DAG is again submitted, using the same command as with the first two submissions, but not repeated here, then this third submission uses the Rescue DAG file my.dag.rescue002, because it exists, and because the value
002 is larger
in magnitude than 001.
To explicitly specify a particular Rescue DAG,
use the optional command-line argument -dorescuefrom
with condor_submit_dag.
Note that this will have the side effect of renaming
existing Rescue DAG files with larger magnitude values
of <XXX>.
Each renamed file has its existing name appended with
the string .old.
For example, assume that my.dag has failed 4 times,
resulting in the Rescue DAGs named
my.dag.rescue001,
my.dag.rescue002,
my.dag.rescue003,
and
my.dag.rescue004.
A decision is made to re-run using my.dag.rescue002.
The submit command is
condor_submit_dag -dorescuefrom 2 my.dagThe DAG specified by the DAG input file my.dag.rescue002 is submitted. And, the existing Rescue DAG my.dag.rescue003 is renamed to be my.dag.rescue003.old, while the existing Rescue DAG my.dag.rescue004 is renamed to be my.dag.rescue004.old.
The configuration variable DAGMAN_MAX_RESCUE_NUM
sets a maximum value for XXX.
See section 3.3.25 for the complete definition
of this configuration variable.
Starting in Condor version 7.5.5, the -DumpRescue option to either condor_dagman or condor_submit_dag causes condor_dagman to output a Rescue DAG file, even if the parsing of a DAG input file fails. In this parse failure case, condor_dagman produces a specially named Rescue DAG containing whatever it had successfully parsed up until the point of the parse error. This Rescue DAG may be useful in debugging parse errors in complex DAGs, especially ones using splices. This incomplete Rescue DAG is not meant to be used when resubmitting a failed DAG. Note that this incomplete Rescue DAG generated by the -DumpRescue option is a full DAG input file, as produced by versions of Condor prior to Condor version 7.7.2. It is not a partial Rescue DAG file, regardless of the value of the configuration variable DAGMAN_WRITE_PARTIAL_RESCUE .
To avoid confusion between this incomplete Rescue DAG generated in the case of a parse failure and a usable Rescue DAG, a different name is given to the incomplete Rescue DAG. The name appends the string .parse_failed to the original DAG input file name. Therefore, if the submission of a DAG with
condor_submit_dag my.daghas a parse failure, the resulting incomplete Rescue DAG will be named my.dag.parse_failed.
To further prevent one of these incomplete Rescue DAG files from being used, a line within the file contains the single keyword REJECT. This causes condor_dagman to reject the DAG, if used as a DAG input file. This is done because the incomplete Rescue DAG may be a syntactically correct DAG input file. It will be incomplete relative to the original DAG, such that if the incomplete Rescue DAG could be run, it could erroneously be perceived as having successfully executed the desired workflow, when, in fact, it did not.
Prior to Condor version 7.1.0, the naming of a Rescue DAG appended the string .rescue to the existing DAG input file name. And, the Rescue DAG file would be explicitly placed in the command line that submitted it. For example, a first submission
condor_submit_dag my.dagAssuming that this DAG failed, the file my.dag.rescue would be created. To run this Rescue DAG, the submission command is
condor_submit_dag my.dag.rescueIf this Rescue DAG also failed, a new Rescue DAG named my.dag.rescue.rescue would be created.
By default, condor_dagman assumes that all relative paths in a DAG input file and the associated Condor submit description files are relative to the current working directory when condor_submit_dag is run. Note that relative paths in submit description files can be modified by the submit command initialdir; see the condor_submit manual page within Chapter 10 for more details. The rest of this discussion ignores initialdir.
In most cases, path names relative to the current working directory is the desired behavior. However, if running multiple DAGs with a single condor_dagman, and each DAG is in its own directory, this will cause problems. In this case, use the -usedagdir command-line argument to condor_submit_dag (see the condor_submit_dag manual page within Chapter 10 for more details). This tells condor_dagman to run each DAG as if condor_submit_dag had been run in the directory in which the relevant DAG file exists.
For example, assume that a directory called parent contains two subdirectories called dag1 and dag2, and that dag1 contains the DAG input file one.dag and dag2 contains the DAG input file two.dag. Further, assume that each DAG is set up to be run from its own directory with the following command:
cd dag1; condor_submit_dag one.dagThis will correctly run one.dag.
The goal is to run the two, independent DAGs located within dag1 and dag2 while the current working directory is parent. To do so, run the following command:
condor_submit_dag -usedagdir dag1/one.dag dag2/two.dag
Of course, if all paths in the DAG input file(s) and the relevant submit description files are absolute, the -usedagdir argument is not needed; however, using absolute paths is NOT generally a good idea.
If you do not use -usedagdir, relative paths can still work for multiple DAGs, if all file paths are given relative to the current working directory as condor_submit_dag is executed. However, this means that, if the DAGs are in separate directories, they cannot be submitted from their own directories, only from the parent directory the paths are set up for.
Note that if you use the -usedagdir argument, and your run results in a rescue DAG, the rescue DAG file will be written to the current working directory, and should be run from that directory. The rescue DAG includes all the path information necessary to run each node job in the proper directory.
It can be helpful to see a picture of a DAG. DAGMan can assist you in visualizing a DAG by creating the input files used by the AT&T Research Labs graphviz package. dot is a program within this package, available from http://www.graphviz.org/, and it is used to draw pictures of DAGs.
DAGMan produces one or more dot files as the result of an extra line in a DAGMan input file. The line appears as
DOT dag.dot
This creates a file called dag.dot. which contains a specification of the DAG before any jobs within the DAG are submitted to Condor. The dag.dot file is used to create a visualization of the DAG by using this file as input to dot. This example creates a Postscript file, with a visualization of the DAG:
dot -Tps dag.dot -o dag.ps
Within the DAGMan input file, the DOT command can take several optional parameters:
DOT dag.dot DONT-OVERWRITE
causes files
dag.dot.0,
dag.dot.1,
dag.dot.2,
etc. to be created.
This option is
most useful when combined with the UPDATE option to
visualize the history of the DAG after it has finished executing.
label=.
This may be useful if further editing of the created files would
be necessary,
perhaps because you are automatically visualizing the DAG as it
progresses.
If conflicting parameters are used in a DOT command, the last one listed is used.
DAGMan can capture the status of all DAG nodes, such that the user or a script may easily monitor the status of all DAG nodes. A node status file is periodically rewritten by DAGMan. To enable this feature, the DAG input file contains a line with the NODE_STATUS_FILE key word.
The syntax for a NODE_STATUS_FILE specification is
NODE_STATUS_FILE statusFileName [minimumUpdateTime]
The status file is written on the machine where the DAG is submitted; its location is given by statusFileName. This will be the same machine where the condor_dagman job is running.
The optional minimumUpdateTime specifies the minimum number of seconds that must elapse between updates to the node status file. This setting exists to avoid having DAGMan spend too much time writing the node status file for very large DAGs. If no value is specified, no limit is set. The node status file can be updated at most once per DAGMAN_USER_LOG_SCAN_INTERVAL , as defined at section 3.3.25, no matter how small the minimumUpdateTime value.
As an example, if the DAG input file contains the line
NODE_STATUS_FILE my.dag.status 30the file my.dag.status will be rewritten at intervals of 30 seconds or more.
This node status file is overwritten each time it is updated. Therefore, it only holds information about the current status of each node; it does not provide a history of the node status. The file contains one line describing the status of every node in the DAG. The file contents do not distinguish between Condor jobs and Stork jobs. Here is an example of a node status file:
BEGIN 1281041745 (Thu Aug 5 15:55:45 2010) Status of nodes of DAG(s): my.dag JOB A STATUS_DONE () JOB B STATUS_SUBMITTED (not_idle) JOB C STATUS_SUBMITTED (idle) JOB D STATUS_UNREADY () DAG status: STATUS_SUBMITTED () Next scheduled update: 1281041775 (Thu Aug 5 15:56:15 2010) END 1281041745 (Thu Aug 5 15:55:45 2010)
Possible node status values are:
STATUS_UNREADY At least one parent has not yet finished.
STATUS_READY All parents have finished, but not yet running.
STATUS_PRERUN The PRE script is running.
STATUS_SUBMITTED The node's Condor or Stork job(s) are in
the queue.
STATUS_POSTRUN The POST script is running.
STATUS_DONE The node has completed successfully.
STATUS_ERROR The node has failed.
A NODE_STATUS_FILE key word inside any splice is ignored. If multiple DAG files are specified on the condor_submit_dag command line, and more than one specifies a node status file, the first specification takes precedence.
DAGMan can produce a machine-readable history of events. The jobstate.log file is designed for use by the Pegasus Workflow Management System, which operates as a layer on top of DAGMan. Pegasus uses the jobstate.log file to monitor the state of a workflow. The jobstate.log file can used by any automated tool for the monitoring of workflows.
DAGMan produces this file when the keyword JOBSTATE_LOG is in the DAG input file. The syntax for JOBSTATE_LOG is
JOBSTATE_LOG JobstateLogFileName
No more than one jobstate.log file can be created by a single instance of condor_dagman. If more than one jobstate.log file is specified, the first file name specified will take effect, and a warning will be printed in the dagman.out file when subsequent JOBSTATE_LOG specifications are parsed. Multiple specifications may exist in the same DAG file, within splices, or within multiple, independent DAGs run with a single condor_dagman instance.
The jobstate.log file can be considered a filtered version of the dagman.out file, in a machine-readable format. It contains the actual node job events that from condor_dagman, plus some additional meta-events.
The jobstate.log file is different from the node status file, in that the jobstate.log file is appended to, rather than being overwritten as the DAG runs. Therefore, it contains a history of the DAG, rather than a snapshot of the current state of the DAG.
There are 5 line types in the jobstate.log file. Each line begins with a Unix timestamp in the form of seconds since the Epoch. Fields within each line are separated by a single space character.
timestamp INTERNAL *** DAGMAN_STARTED dagmanCondorID ***
The dagmanCondorID field is the condor_dagman job's ClusterId attribute, a period, and the ProcId attribute.
timestamp INTERNAL *** DAGMAN_FINISHED exitCode ***
The exitCode field is value the condor_dagman job returns upon exit.
timestamp INTERNAL *** RECOVERY_STARTED ***
The formatting of the line is
timestamp INTERNAL *** RECOVERY_FINISHED ***
or
timestamp INTERNAL *** RECOVERY_FAILURE ***
timestamp JobName eventName condorID jobTag - sequenceNumber
The JobName is the name given to the node job as defined in the DAG input file with the keyword JOB. It identifies the node within the DAG.
The eventName is one of the many defined event or meta-events given in the lists below.
The condorID field is the job's ClusterId attribute, a period, and the ProcId attribute. There is no condorID assigned yet for some meta-events, such as PRE_SCRIPT_STARTED. For these, the dash character ('-') is printed.
The jobTag field is defined for the Pegasus workflow manager. Its usage is generalized to be useful to other workflow managers. Pegasus-managed jobs add a line of the following form to their Condor submit description file:
+pegasus_site = "local"This defines the string local as the jobTag field.
Generalized usage adds a set of 2 commands to the Condor submit description file to define a string as the jobTag field:
+job_tag_name = "+job_tag_value" +job_tag_value = "viz"This defines the string viz as the jobTag field. Without any of these added lines within the Condor submit description file, the dash character ('-') is printed for the jobTag field.
The sequenceNumber is a monotonically-increasing number that starts at one. It is associated with each attempt at running a node. If a node is retried, it gets a new sequence number; a submit failure does not result in a new sequence number. When a rescue DAG is run, the sequence numbers pick up from where they left off within the previous attempt at running the DAG. Note that this only applies if the rescue DAG is run automatically or with the -dorescuefrom command-line option.
Here is an example of a very simple Pegasus jobstate.log file, assuming the example jobTag field of local:
1292620511 INTERNAL *** DAGMAN_STARTED 4972.0 *** 1292620523 NodeA PRE_SCRIPT_STARTED - local - 1 1292620523 NodeA PRE_SCRIPT_SUCCESS - local - 1 1292620525 NodeA SUBMIT 4973.0 local - 1 1292620525 NodeA EXECUTE 4973.0 local - 1 1292620526 NodeA JOB_TERMINATED 4973.0 local - 1 1292620526 NodeA JOB_SUCCESS 0 local - 1 1292620526 NodeA POST_SCRIPT_STARTED 4973.0 local - 1 1292620531 NodeA POST_SCRIPT_TERMINATED 4973.0 local - 1 1292620531 NodeA POST_SCRIPT_SUCCESS 4973.0 local - 1 1292620535 INTERNAL *** DAGMAN_FINISHED 0 ***
Using DAGMan is recommended when submitting large numbers of jobs. The recommendation holds whether the jobs are represented by a DAG due to dependencies, or all the jobs are independent of each other, such as they might be in a parameter sweep. DAGMan offers:
Each of these capabilities is described in detail (above) within this manual section about DAGMan. To make effective use of DAGMan, there is no way around reading the appropriate subsections.
To run DAGMan with large numbers of independent jobs, there are generally two ways of organizing and specifying the files that control the jobs. Both ways presume that programs or scripts will generate the files, because the files are either large and repetitive or because there are a large number of similar files to be generated representing the large numbers of jobs. The two file types needed are the DAG input file and the submit description file(s) for the Condor jobs represented. Each of the two ways is presented separately:
# file sweep.dag JOB job0 job0.submit JOB job1 job1.submit JOB job2 job2.submit . . . JOB job999 job999.submitThere are 1000 submit description files, with a unique one for each of the job<N> jobs. Assuming that all files associated with this set of jobs are in the same directory, and that files continue the same naming and numbering scheme, the submit description file for job6.submit might appear as
# file job6.submit universe = vanilla executable = /path/to/executable log = job6.log input = job6.in output = job6.out notification = Never arguments = "-file job6.out" queue
Submission of the entire set of jobs is
condor_submit_dag sweep.dag
A benefit to having unique submit description files for each of the jobs is that they are available, if one of the jobs needs to be submitted individually. A drawback to having unique submit description files for each of the jobs is that there are lots of files, one for each job.
# file sweep.dag JOB job0 common.submit VARS job0 runnumber="0" JOB job1 common.submit VARS job1 runnumber="1" JOB job2 common.submit VARS job2 runnumber="2" . . . JOB job999 common.submit VARS job999 runnumber="999"
The single submit description file for all these jobs utilizes the runnumber variable value in its identification of the job's files. This submit description file might appear as
# file common.submit universe = vanilla executable = /path/to/executable log = wholeDAG.log input = job$(runnumber).in output = job$(runnumber).out notification = Never arguments = "-$(runnumber)" queueThe job with runnumber="8" expects to find its input file job8.in in the single, common directory, and it sends its output to job8.out. The single log for all job events of the entire DAG is wholeDAG.log. Using one file for the entire DAG meets the limitation that no macro substitution may be specified for the job log file, and it is likely more efficient as well. This node's executable is invoked with
/path/to/executable -8
These examples work well with respect to file naming and placement when there are less than several thousand jobs submitted as part of a DAG. The large numbers of files per directory becomes an issue when there are greater than several thousand jobs submitted as part of a DAG. In this case, consider a more hierarchical structure for the files instead of a single directory. Introduce a separate directory for each run. For example, if there were 10,000 jobs, there would be 10,000 directories, one for each of these jobs. The directories are presumed to be generated and populated by programs or scripts that, like the previous examples, utilize a run number. Each of these directories named utilizing the run number will be used for the input, output, and log files for one of the many jobs.
As an example, for this set of 10,000 jobs and directories, assume that there is a run number of 600. The directory will be named dir.600, and it will hold the 3 files called in, out, and log, representing the input, output, and Condor job log files associated with run number 600.
The DAG input file sets a variable representing the run number, as in the previous example:
# file biggersweep.dag JOB job0 common.submit VARS job0 runnumber="0" JOB job1 common.submit VARS job1 runnumber="1" JOB job2 common.submit VARS job2 runnumber="2" . . . JOB job9999 common.submit VARS job9999 runnumber="9999"
A single Condor submit description file may be written. It resides in the same directory as the DAG input file.
# file bigger.submit universe = vanilla executable = /path/to/executable log = log input = in output = out notification = Never arguments = "-$(runnumber)" initialdir = dir.$(runnumber) queue
One item to care about with this set up is the underlying file system for the pool. The transfer of files (or not) when using initialdir differs based upon the job universe and whether or not there is a shared file system. See section 10 for the details on the submit command initialdir.
Submission of this set of jobs is no different than the previous examples. With the current working directory the same as the one containing the submit description file, the DAG input file, and the subdirectories,
condor_submit_dag biggersweep.dag