Figure 2
in
Section 1.2
illustrates the process structure of Shore.
Shore executes as a group of communicating processes called SHORE
servers. Shore servers consist exclusively of trusted code,
including those parts of the system that are provided as
part of the standard Shore release, as well as code for
value-added servers.
that can be added by sophisticated users to implement
specialized facilities (e.g., a query-shipping SQL server) without
introducing the ``client-level server'' problem described earlier.
Application processes (labelled ``App'' in
Figure 2
manipulate objects, while servers deal primarily with fixed-length
pages allocated from disk volumes, each of which is
managed by a single server.![]() Applications are not trusted, in the sense that a buggy or malicious
application can only modify objects that it is authorized to access; in
particular,
it cannot corrupt metadata such as slot tables, indexes, or the directory
structure.
Applications are not trusted, in the sense that a buggy or malicious
application can only modify objects that it is authorized to access; in
particular,
it cannot corrupt metadata such as slot tables, indexes, or the directory
structure.
Each Shore server plays several roles.
First, it is a page-cache manager. The cache may contain pages from
local volumes as well as pages from remote servers containing objects
that were requested by local client applications.![]() Second, the server acts as an agent for local application processes.
When an application needs an object, it sends an RPC request to
the local server, which fetches the necessary page(s) and returns the object.
(More details are provided in the following section.)
Finally, the Shore server is responsible for concurrency control and recovery.
A server obtains and caches locks on behalf of its local clients.
The owner of each page (the server that manages its volume) is
responsible for arbitrating lock requests for its objects, as well as
logging and committing changes to it.
Transaction management is described in more detail below.
Second, the server acts as an agent for local application processes.
When an application needs an object, it sends an RPC request to
the local server, which fetches the necessary page(s) and returns the object.
(More details are provided in the following section.)
Finally, the Shore server is responsible for concurrency control and recovery.
A server obtains and caches locks on behalf of its local clients.
The owner of each page (the server that manages its volume) is
responsible for arbitrating lock requests for its objects, as well as
logging and committing changes to it.
Transaction management is described in more detail below.
This process structure provides a great deal of flexibility. When acting as an owner of a page, the Shore server performs the role of the server in a traditional data-shipping, client-server DBMS; when acting as the agent for an application, it plays the role of client. Letting the Shore server assume both roles allows data placement to be optimized according to workload. For example, data that is largely private to a single user could be owned by the Shore server on that user's workstation. The location-transparency (from the application's viewpoint) provided by the caching-based architecture allows an application on such a workstation to access both local and remote persistent data in an identical manner. Furthermore, the ability to cache pages at the local server can greatly reduce any observed performance penalty for accessing remote data. In Figure 2, applications running on Workstation 2 can access data that is largely private through the local Shore server, while obtaining other shared data from the other Shore servers. With a query-shipping architecture implemented by a ``higher level'' value-added server (such as an SQL server), applications would communicate directly with remote servers.
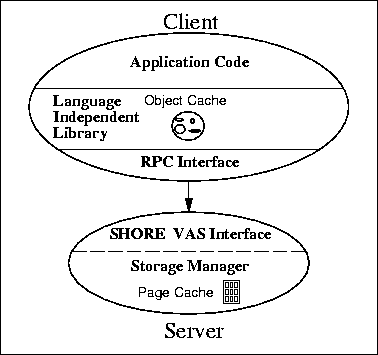
Figure 7
depicts the components of the Shore software
linked with each application.
When the application attempts to dereference an ``unswizzled'' pointer,
the language binding generates a call to the
object-cache manager (OC)
in the
language-independent library (LIL).
To avoid paging, the object cache manager locks the cache in memory and uses LRU replacement if it grows too large All OIDs in the cache are swizzled to point to entries in an object table. This level of indirection allows objects to be removed from memory before the transaction commits, without the need to track down and unswizzle all pointers to them.
The LIL also contains the Unix compatibility library, with procedures that
emulate common file system calls such as open, read, and seek.
Finally, the LIL is responsible for
authenticating the application to the server using
the Kerberos authentication system [MNSS87]![]() .
.
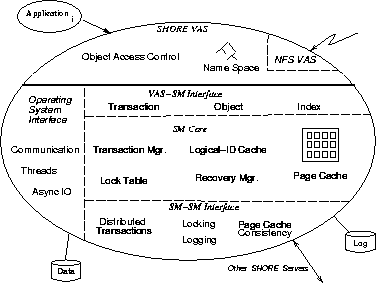
Figure 8 shows the internal structure of the Shore server in more detail. It is divided into several components, including the Shore Value-Added Server, which communicates with applications, and the Shore Storage Manager (SSM), which manages the persistent object store.
The Shore Value-Added Server (SVAS) is responsible for providing access to Shore objects stored in the SSM. It manages the Unix-like name space and other structures described in Section 2.3. When an application connects with the server, the server associates Unix-like process state (such as a user ID and current directory name) with the connection. User ID information is checked against registered objects when they are first accessed to protect against unauthorized access. As in Unix, the current directory name information provides a context for converting file (path) names into absolute locations in the name space.
The SVAS is one example of a value-added server. Another value-added server is the NFS server described in Section 2.3.2. Each value-added server provides an alternative interface to the storage manager. They all interact with the storage manager through a common interface that is similar to the RPC interface between application processes and the server. A goal of Shore is to make it possible to debug a new value-added server as a client process and then migrate it into the server for added efficiency when it is completely debugged.
Another example of a value-added server could be an SQL
server that provides a query-shipping
interface to a relational database.![]()
Below the server interface lies the Storage Manager. As shown in Figure 8, the SSM can be viewed as having three sub-layers. The highest is the value-added server-to-SSM interface, which consists primarily of functions to control transactions and to access objects and indexes. The middle level comprises the core of the SSM. It implements records, indexes, transactions, concurrency control, and recovery. At the lowest level are extensions to the core that implement the distributed server capabilities described in Section 3.1. In addition to these three layers, the SSM contains an operating system interface that packages together multi-threading, asynchronous I/O, and inter-process communication.
A detailed description of the storage manager is beyond the scope of this document. However, in this subsection we highlight three of the important technical issues that arise in its implementation: cache consistency, transaction management, and object identifier implementation.
In Shore, there are two types of caches--the object caches used by
applications and the page caches maintained by Shore servers. These
two types of caches are managed very differently. The Shore servers'
page caches are allowed to retain their contents across transaction
boundaries (called inter-transaction caching). Cache
consistency is maintained through the use of a callback locking
protocol [HMN+88,LLOW91,WR91,FC92]![]() .
The application/server interface, however does not support ``upcalls.''
Requiring application processes to respond to remote procedure calls
would interfere with other synchronization mechanisms used by many
application programs such as threads packages, graphics (X11 or InterViews),
and networking interfaces. Therefore, the object cache is invalidated
(and locks are released) at the end of a transaction.
We plan to explore techniques to extend the use of
the object cache across transaction boundaries later in the Shore project.
.
The application/server interface, however does not support ``upcalls.''
Requiring application processes to respond to remote procedure calls
would interfere with other synchronization mechanisms used by many
application programs such as threads packages, graphics (X11 or InterViews),
and networking interfaces. Therefore, the object cache is invalidated
(and locks are released) at the end of a transaction.
We plan to explore techniques to extend the use of
the object cache across transaction boundaries later in the Shore project.
To balance efficiency against the need for fine-grain concurrency,
Shore uses an adaptive version of callback locking that
can dynamically adjust the granularity (e.g., page vs. object)
at which locking is performed depending on the presence of data
conflicts [CFZ93]. This adaptive algorithm is based on the
notion of lock de-escalation [LC89,Jos91].![]()
When an application wishes to commit a transaction, a commit request is sent to its local server. If the transaction has modified data that is owned by multiple servers, then a two-phase commit protocol is used among the relevant servers. If the local server has a log, it will coordinate the distributed commit protocol; otherwise, it will delegate the coordinator role to another server. Transactions that only access data that is owned by the local server can commit locally. Thus, the peer-to-peer architecture incurs the additional overhead of distributed commit only when it is necessary.
The transaction rollback and recovery facilities of Shore are based on
the ARIES recovery algorithm
[MHL+92] extended for the
client-server environment of Shore. The client-server distinction
reflects the roles played by the server with respect to an object. A
server that owns an object is the one that stores the log for that
object and that performs all recovery operations on the object.
Servers caching the object behave as clients and generate log records
that are shipped to the owner of the object. The initial server-to-server
implementation of Shore relies on a simple extension of ARIES that we
call redo-at-server. In this extension, a client never ships
dirty pages back to the server, only log records; when the server receives
log records from a client, it redoes the operations indicated by the log
records. This is easy to implement, and it has the advantage of eliminating
the need to send dirty pages back to the server.![]() The primary disadvantage is that the server may need to reread pages if
it has flushed them from its cache.
In the future, we plan to implement the
client-server extension to ARIES that was developed and implemented
for the EXODUS Storage Manager [FZT+92] and compare its
performance to our simpler redo-at-server implementation.
The primary disadvantage is that the server may need to reread pages if
it has flushed them from its cache.
In the future, we plan to implement the
client-server extension to ARIES that was developed and implemented
for the EXODUS Storage Manager [FZT+92] and compare its
performance to our simpler redo-at-server implementation.
The implementation of object identifiers (OIDs) has a considerable impact on how the rest of an object manager is implemented and on its performance. The Shore Storage Manager uses two types of OIDs. A physical OID records the actual location of an object on disk, while a logical OID is position independent, allowing transparent reorganization such as reclustering. The higher levels of Shore (including the object cache manager) use logical OIDs to represent object references.
A logical OID consists of an 8-byte volume identifier and an 8-byte serial number. The former is designed to be long enough to allow it be globally unique, allowing independently developed databases to be combined. The latter is large enough to avoid reuse of values under any conceivable operating conditions. When an OID is stored on disk, only the serial number is recorded. The volume identifier is assumed to be the same as the volume containing the OID. For cross-volume references, the serial number identifies a special forwarding entry that contains the full OID of the object (the identifier of the volume that contains it and its serial number relative to that volume).
To map serial numbers to physical OIDs or remote logical OIDs, each volume contains a B+ tree index called its LID index. An in-memory hash table is used to cache recently translated entries. The server also eagerly adds translations to this per-transaction translation cache. For example, whenever a server receives a request for an object whose logical OID is not currently in the cache, it requests the page containing that object from the object's server. When that page arrives, the server enters mappings for all of the objects on that page into the translation cache. This technique effectively reduces the number of LID index accesses from one lookup per object to one lookup per page of objects.