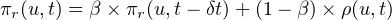
HTCondor uses priorities to determine machine allocation for jobs. This section details the priorities and the allocation of machines (negotiation).
For accounting purposes, each user is identified by username@uid_domain. Each user is assigned a priority value even if submitting jobs from different machines in the same domain, or even if submitting from multiple machines in the different domains.
The numerical priority value assigned to a user is inversely related to the goodness of the priority. A user with a numerical priority of 5 gets more resources than a user with a numerical priority of 50. There are two priority values assigned to HTCondor users:
This section describes these two priorities and how they affect resource allocations in HTCondor. Documentation on configuring and controlling priorities may be found in section 3.5.15.
A user’s RUP measures the resource usage of the user through time. Every user begins with a RUP of one half (0.5), and at steady state, the RUP of a user equilibrates to the number of resources used by that user. Therefore, if a specific user continuously uses exactly ten resources for a long period of time, the RUP of that user stabilizes at ten.
However, if the user decreases the number of resources used, the RUP gets better. The rate at which the priority value decays can be set by the macro PRIORITY_HALFLIFE , a time period defined in seconds. Intuitively, if the PRIORITY_HALFLIFE in a pool is set to 86400 (one day), and if a user whose RUP was 10 has no running jobs, that user’s RUP would be 5 one day later, 2.5 two days later, and so on.
The effective user priority (EUP) of a user is used to determine how many resources that user may receive. The EUP is linearly related to the RUP by a priority factor which may be defined on a per-user basis. Unless otherwise configured, an initial priority factor for all users as they first submit jobs is set by the configuration variable DEFAULT_PRIO_FACTOR , and defaults to the value 1000.0. If desired, the priority factors of specific users can be increased using condor_userprio, so that some are served preferentially.
The number of resources that a user may receive is inversely related to the ratio between the EUPs of submitting users. Therefore user A with EUP=5 will receive twice as many resources as user B with EUP=10 and four times as many resources as user C with EUP=20. However, if A does not use the full number of resources that A may be given, the available resources are repartitioned and distributed among remaining users according to the inverse ratio rule.
HTCondor supplies mechanisms to directly support two policies in which EUP may be useful:
The priority boost factors for individual users can be set with the setfactor option of condor_userprio. Details may be found in the condor_userprio manual page on page 2339.
Priorities are used to ensure that users get their fair share of resources. The priority values are used at allocation time, meaning during negotiation and matchmaking. Therefore, there are ClassAd attributes that take on defined values only during negotiation, making them ephemeral. In addition to allocation, HTCondor may preempt a machine claim and reallocate it when conditions change.
Too many preemptions lead to thrashing, a condition in which negotiation for a machine identifies a new job with a better priority most every cycle. Each job is, in turn, preempted, and no job finishes. To avoid this situation, the PREEMPTION_REQUIREMENTS configuration variable is defined for and used only by the condor_negotiator daemon to specify the conditions that must be met for a preemption to occur. When preemption is enabled, it is usually defined to deny preemption if a current running job has been running for a relatively short period of time. This effectively limits the number of preemptions per resource per time interval. Note that PREEMPTION_REQUIREMENTS only applies to preemptions due to user priority. It does not have any effect if the machine’s RANK expression prefers a different job, or if the machine’s policy causes the job to vacate due to other activity on the machine. See section 3.7.1 for the current default policy on preemption.
The following ephemeral attributes may be used within policy definitions. Care should be taken when using these attributes, due to their ephemeral nature; they are not always defined, so the usage of an expression to check if defined such as
is likely necessary.
Within these attributes, those with names that contain the string Submitter refer to characteristics about the candidate job’s user; those with names that contain the string Remote refer to characteristics about the user currently using the resource. Further, those with names that end with the string ResourcesInUse have values that may change within the time period associated with a single negotiation cycle. Therefore, the configuration variables PREEMPTION_REQUIREMENTS_STABLE and and PREEMPTION_RANK_STABLE exist to inform the condor_negotiator daemon that values may change. See section 3.5.15 on page 741 for definitions of these configuration variables.
This section may be skipped if the reader so feels, but for the curious, here is HTCondor’s priority calculation algorithm.
The RUP of a user u at time t, πr(u,t), is calculated every time interval δt using the formula
The EUP of user u at time t, πe(u,t) is calculated by
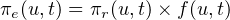
As mentioned previously, the RUP calculation is designed so that at steady state, each user’s RUP stabilizes at the number of resources used by that user. The definition of β ensures that the calculation of πr(u,t) can be calculated over non-uniform time intervals δt without affecting the calculation. The time interval δt varies due to events internal to the system, but HTCondor guarantees that unless the central manager machine is down, no matches will be unaccounted for due to this variance.
Negotiation is the method HTCondor undergoes periodically to match queued jobs with resources capable of running jobs. The condor_negotiator daemon is responsible for negotiation.
During a negotiation cycle, the condor_negotiator daemon accomplishes the following ordered list of items.
The condor_negotiator asks the condor_schedd for the "next job" from a given submitter/user. Typically, the condor_schedd returns jobs in the order of job priority. If priorities are the same, job submission time is used; older jobs go first. If a cluster has multiple procs in it and one of the jobs cannot be matched, the condor_schedd will not return any more jobs in that cluster on that negotiation pass. This is an optimization based on the theory that the cluster jobs are similar. The configuration variable NEGOTIATE_ALL_JOBS_IN_CLUSTER disables the cluster-skipping optimization. Use of the configuration variable SIGNIFICANT_ATTRIBUTES will change the definition of what the condor_schedd considers a cluster from the default definition of all jobs that share the same ClusterId.
HTCondor schedules in a variety of ways. First, it takes all users who have submitted jobs and calculates their priority. Then, it totals the number of resources available at the moment, and using the ratios of the user priorities, it calculates the number of machines each user could get. This is their pie slice.
The HTCondor matchmaker goes in user priority order, contacts each user, and asks for job information. The condor_schedd daemon (on behalf of a user) tells the matchmaker about a job, and the matchmaker looks at available resources to create a list of resources that match the requirements expression. With the list of resources that match, it sorts them according to the rank expressions within ClassAds. If a machine prefers a job, the job is assigned to that machine, potentially preempting a job that might already be running on that machine. Otherwise, give the machine to the job that the job ranks highest. If the machine ranked highest is already running a job, we may preempt running job for the new job. When preemption is enabled, a reasonable policy states that the user must have a 20% better priority in order for preemption to succeed. If the job has no preferences as to what sort of machine it gets, matchmaking gives it the first idle resource to meet its requirements.
This matchmaking cycle continues until the user has received all of the machines in their pie slice. The matchmaker then contacts the next highest priority user and offers that user their pie slice worth of machines. After contacting all users, the cycle is repeated with any still available resources and recomputed pie slices. The matchmaker continues spinning the pie until it runs out of machines or all the condor_schedd daemons say they have no more jobs.
By default, HTCondor does all accounting on a per-user basis, and this accounting is primarily used to compute priorities for HTCondor’s fair-share scheduling algorithms. However, accounting can also be done on a per-group basis. Multiple users can all submit jobs into the same accounting group, and all jobs with the same accounting group will be treated with the same priority. Jobs that do not specify an accounting group have all accounting and priority based on the user, which may be identified by the job ClassAd attribute Owner. Jobs that do specify an accounting group have all accounting and priority based on the specified accounting group. Therefore, accounting based on groups only works when the jobs correctly identify their group membership.
The preferred method for having a job associate itself with an accounting group adds a command to the submit description file that specifies the group name:
This command causes the job ClassAd attribute AcctGroup to be set with this group name.
If the user name of the job submitter should be other than the Owner job ClassAd attribute, an additional command specifies the user name:
This command causes the job ClassAd attribute AcctGroupUser to be set with this user name.
The previous method for defining accounting groups is no longer recommended. It inserted the job ClassAd attribute AccountingGroup by setting it in the submit description file using the syntax in this example:
In this previous method for defining accounting groups, the AccountingGroup attribute is a string, and it therefore must be enclosed in double quote marks.
Much of the reason that the previous method for defining accounting groups is no longer recommended is that the name of an accounting is that it used the period (.) character to separate the group name from the user name. Therefore, the syntax did not work if a user name contained a period.
The name should not be qualified with a domain. Certain parts of the HTCondor system do append the value $(UID_DOMAIN) (as specified in the configuration file on the submit machine) to this string for internal use. For example, if the value of UID_DOMAIN is example.com, and the accounting group name is as specified, condor_userprio will show statistics for this accounting group using the appended domain, for example
Additionally, the condor_userprio command allows administrators to remove an entity from the accounting system in HTCondor. The -delete option to condor_userprio accomplishes this if all the jobs from a given accounting group are completed, and the administrator wishes to remove that group from the system. The -delete option identifies the accounting group with the fully-qualified name of the accounting group. For example
HTCondor removes entities itself as they are no longer relevant. Intervention by an administrator to delete entities can be beneficial when the use of thousands of short term accounting groups leads to scalability issues.
An upper limit on the number of slots allocated to a group of users can be specified with group quotas. This policy may be desired when different groups provide their computers to create one large HTCondor pool, and want to restrict the number of jobs running from one group to the number of machines the group has provided.
Consider an example pool with thirty slots: twenty slots are owned by the physics group and ten are owned by the chemistry group. The desired policy is that no more than twenty concurrent jobs are ever running from the physicists, and only ten from the chemists. These machines are otherwise identical, so it does not matter which machines run which group’s jobs. It only matters that the proportions of allocated slots are correct.
Instead of quotas, this could be implemented by configuring the RANK expression such that the twenty machines owned by the physics group prefer jobs submitted by the physics users. Likewise, the ten machines owned by the chemistry group are configured to prefer jobs submitted by the chemistry group. However, this steers jobs to execute on specific machines, instead of the desired policy which allocates numbers of machines, where these machines can be any of the pool’s machines that are available.
Group quotas may implement this policy. Define the groups and set their quotas in the configuration of the central manager:
The implementation of quotas is hierarchical, such that quotas may be described for the tree of groups, subgroups, sub subgroups, etc. Group names identify the groups, such that the configuration can define the quotas in terms of limiting the number of cores allocated for a group or subgroup. Group names do not need to begin with "group_", but that is the convention, which helps to avoid naming conflicts between groups and subgroups. The hierarchy is identified by using the period (’.’) character to separate a group name from a subgroup name from a sub subgroup name, etc. Group names are case-insensitive for negotiation.
At the root of the tree that defines the hierarchical groups is the invented "<none>" group. The implied quota of the "<none>" group will be all available slots. This string will appear in the output of condor_status.
If the sum of the child quotas exceeds the parent, then the child quotas are scaled down in proportion to their relative sizes. For the given example, there were 30 original slots at the root of the tree. If a power failure removed half of the original 30, leaving fifteen slots, physics would be scaled back to a quota of ten, and chemistry to five. This scaling can be disabled by setting the condor_negotiator configuration variable NEGOTIATOR_ALLOW_QUOTA_OVERSUBSCRIPTION to True. If the sum of the child quotas is less than that of the parent, the child quotas remain intact; they are not scaled up. That is, if somehow the number of slots doubled from thirty to sixty, physics would still be limited to 20 slots, and chemistry would be limited to 10. This example in which the quota is defined by absolute values is called a static quota.
Each job must state which group it belongs to. Currently this is opt-in, and the system trusts each user to put the correct group in the submit description file. Jobs that do not identify themselves as a group member are negotiated for as part of the "<none>" group. Note that this requirement is per job, not per user. A given user may be a member of many groups. Jobs identify which group they are in by setting the accounting_group and accounting_group_user commands within the submit description file, as specified in section 3.6.7. For example:
The size of the quotas may instead be expressed as a proportion. This is then referred to as a dynamic group quota, because the size of the quota is dynamically recalculated every negotiation cycle, based on the total available size of the pool. Instead of using static quotas, this example can be recast using dynamic quotas, with one-third of the pool allocated to chemistry and two-thirds to physics. The quotas maintain this ratio even as the size of the pool changes, perhaps because of machine failures, because of the arrival of new machines within the pool, or because of other reasons. The job submit description files remain the same. Configuration on the central manager becomes:
The values of the quotas must be less than 1.0, indicating fractions of the pool’s machines. As with static quota specification, if the sum of the children exceeds one, they are scaled down proportionally so that their sum does equal 1.0. If their sum is less than one, they are not changed.
Extending this example to incorporate subgroups, assume that the physics group consists of high-energy (hep) and low-energy (lep) subgroups. The high-energy sub-group owns fifteen of the twenty physics slots, and the low-energy group owns the remainder. Groups are distinguished from subgroups by an intervening period character (.) in the group’s name. Static quotas for these subgroups extend the example configuration:
This hierarchy may be more useful when dynamic quotas are used. Here is the example, using dynamic quotas:
The fraction of a subgroup’s quota is expressed with respect to its parent group’s quota. That is, the high-energy physics subgroup is allocated 75% of the 66% that physics gets of the entire pool, however many that might be. If there are 30 machines in the pool, that would be the same 15 machines as specified in the static quota example.
High-energy physics users indicate which group their jobs should go in with the submit description file identification:
In all these examples so far, the hierarchy is merely a notational convenience. Each of the examples could be implemented with a flat structure, although it might be more confusing for the administrator. Surplus is the concept that creates a true hierarchy.
If a given group or sub-group accepts surplus, then that given group is allowed to exceed its configured quota, by using the leftover, unused quota of other groups. Surplus is disabled for all groups by default. Accepting surplus may be enabled for all groups by setting GROUP_ACCEPT_SURPLUS to True. Surplus may be enabled for individual groups by setting GROUP_ACCEPT_SURPLUS_<groupname> to True. Consider the following example:
This configuration is the same as above for the chemistry users. However, GROUP_ACCEPT_SURPLUS is set to False globally, False for the physics parent group, and True for the subgroups group_physics.lep and group_physics.lep. This means that group_physics.lep and group_physics.hep are allowed to exceed their quota of 15 and 5, but their sum cannot exceed 20, for that is their parent’s quota. If the group_physics had GROUP_ACCEPT_SURPLUS set to True, then either group_physics.lep and group_physics.hep would not be limited by quota.
Surplus slots are distributed bottom-up from within the quota tree. That is, any leaf nodes of this tree with excess quota will share it with any peers which accept surplus. Any subsequent excess will then be passed up to the parent node and over to all of its children, recursively. Any node that does not accept surplus implements a hard cap on the number of slots that the sum of it’s children use.
After the condor_negotiator calculates the quota assigned to each group, possibly adding in surplus, it then negotiates with the condor_schedd daemons in the system to try to match jobs to each group. It does this one group at a time. By default, it goes in "starvation group order." That is, the group whose current usage is the smallest fraction of its quota goes first, then the next, and so on. The "<none>" group implicitly at the root of the tree goes last. This ordering can be replaced by defining configuration variable GROUP_SORT_EXPR . The condor_negotiator evaluates this ClassAd expression for each group ClassAd, sorts the groups by the floating point result, and then negotiates with the smallest positive value going first. Available attributes for sorting with GROUP_SORT_EXPR include:
| Attribute Name | Description |
| AccountingGroup | A string containing the group name |
| GroupQuota | The computed limit for this group |
| GroupQuotaInUse | The total slot weight used by this group |
| GroupQuotaAllocated | Quota allocated this cycle |
One possible group quota policy is strict priority. For example, a site prefers physics users to match as many slots as they can, and only when all the physics jobs are running, and idle slots remain, are chemistry jobs allowed to run. The default "starvation group order" can be used to implement this. By setting configuration variable NEGOTIATOR_ALLOW_QUOTA_OVERSUBSCRIPTION to True, and setting the physics quota to a number so large that it cannot ever be met, such as one million, the physics group will always be the "most starving" group, will always negotiate first, and will always be unable to meet the quota. Only when all the physics jobs are running will the chemistry jobs then run. If the chemistry quota is set to a value smaller than physics, but still larger than the pool, this policy can support a third, even lower priority group, and so on.
The condor_userprio command can show the current quotas in effect, and the current usage by group. For example:
This shows that there are two groups, each with 60 jobs in the queue. group_physics.hep has a quota of 15 machines, and group_physics.lep has 5 machines. Other options to condor_userprio, such as -most will also show the number of resources in use.