Note: configuration templates make it easier to implement certain policies; see information on policy templates here: 3.4.2.
Understanding the configuration requires an understanding of ClassAd expressions, which are detailed in section 4.1.
Each machine runs one condor_startd daemon. Each machine may contain one or more cores (or CPUs). The HTCondor construct of a slot describes the unit which is matched to a job. Each slot may contain one or more integer number of cores. Each slot is represented by its own machine ClassAd, distinguished by the machine ClassAd attribute Name, which is of the form slot<N>@hostname. The value for <N> will also be defined with machine ClassAd attribute SlotID.
Each slot has its own machine ClassAd, and within that ClassAd, its own state and activity. Other policy expressions are propagated or inherited from the machine configuration by the condor_startd daemon, such that all slots have the same policy from the machine configuration. This requires configuration expressions to incorporate the SlotID attribute when policy is intended to be individualized based on a slot. So, in this discussion of policy expressions, where a machine is referenced, the policy can equally be applied to a slot.
The condor_startd daemon represents the machine on which it is running to the HTCondor pool. The daemon publishes characteristics about the machine in the machine's ClassAd to aid matchmaking with resource requests. The values of these attributes may be listed by using the command:
condor_status -l hostname
The most important expression to the condor_startd is the START expression. This expression describes the conditions that must be met for a machine or slot to run a job. This expression can reference attributes in the machine's ClassAd (such as KeyboardIdle and LoadAvg) and attributes in a job ClassAd (such as Owner, Imagesize, and Cmd, the name of the executable the job will run). The value of the START expression plays a crucial role in determining the state and activity of a machine.
The Requirements expression is used for matching machines with jobs.
For platforms that support standard universe jobs, the condor_startd defines the Requirements expression by logically anding the START expression and the IS_VALID_CHECKPOINT_PLATFORM expression.
In situations where a machine wants to make itself unavailable for further matches, the Requirements expression is set to False. When the START expression locally evaluates to True, the machine advertises the Requirements expression as True and does not publish the START expression.
Normally, the expressions in the machine ClassAd are evaluated against certain request ClassAds in the condor_negotiator to see if there is a match, or against whatever request ClassAd currently has claimed the machine. However, by locally evaluating an expression, the machine only evaluates the expression against its own ClassAd. If an expression cannot be locally evaluated (because it references other expressions that are only found in a request ClassAd, such as Owner or Imagesize), the expression is (usually) undefined. See section 4.1 for specifics on how undefined terms are handled in ClassAd expression evaluation.
A note of caution is in order when modifying the START expression to reference job ClassAd attributes. When using the POLICY : Desktop configuration template, the IS_OWNER expression is a function of the START expression:
START =?= FALSESee a detailed discussion of the IS_OWNER expression in section 3.7.1. However, the machine locally evaluates the IS_OWNER expression to determine if it is capable of running jobs for HTCondor. Any job ClassAd attributes appearing in the START expression, and hence in the IS_OWNER expression, are undefined in this context, and may lead to unexpected behavior. Whenever the START expression is modified to reference job ClassAd attributes, the IS_OWNER expression should also be modified to reference only machine ClassAd attributes.
NOTE: If you have machines with lots of real memory and swap space such that the only scarce resource is CPU time, consider defining JOB_RENICE_INCREMENT so that HTCondor starts jobs on the machine with low priority. Then, further configure to set up the machines with:
START = True SUSPEND = False PREEMPT = False KILL = FalseIn this way, HTCondor jobs always run and can never be kicked off from activity on the machine. However, because they would run with the low priority, interactive response on the machines will not suffer. A machine user probably would not notice that HTCondor was running the jobs, assuming you had enough free memory for the HTCondor jobs such that there was little swapping.
A checkpoint is the platform-dependent information necessary to continue the execution of a standard universe job. Therefore, the machine (platform) upon which a job executed and produced a checkpoint limits the machines (platforms) which may use the checkpoint to continue job execution. This platform-dependent information is no longer the obvious combination of architecture and operating system, but may include subtle items such as the difference between the normal, bigmem, and hugemem kernels within the Linux operating system. This results in the incorporation of a separate expression to indicate the ability of a machine to resume and continue the execution of a job that has produced a checkpoint. The REQUIREMENTS expression is dependent on this information.
At a high level, IS_VALID_CHECKPOINT_PLATFORM is an expression which becomes true when a job's checkpoint platform matches the current checkpointing platform of the machine. Since this expression is anded with the START expression to produce the REQUIREMENTS expression, it must also behave correctly when evaluating in the context of jobs that are not standard universe.
In words, the current default policy for this expression:
Any non standard universe job may run on this machine. A standard universe job may run on machines with the new checkpointing identification system. A standard universe job may run if it has not yet produced a first checkpoint. If a standard universe job has produced a checkpoint, then make sure the checkpoint platforms between the job and the machine match.
The following is the default boolean expression for this policy. A JobUniverse value of 1 denotes the standard universe. This expression may be overridden in the HTCondor configuration files.
IS_VALID_CHECKPOINT_PLATFORM =
(
(TARGET.JobUniverse =!= 1) ||
(
(MY.CheckpointPlatform =!= UNDEFINED) &&
(
(TARGET.LastCheckpointPlatform =?= MY.CheckpointPlatform) ||
(TARGET.NumCkpts == 0)
)
)
)
IS_VALID_CHECKPOINT_PLATFORM is a separate policy expression because the complexity of IS_VALID_CHECKPOINT_PLATFORM can be very high. While this functionality is conceptually separate from the normal START policies usually constructed, it is also a part of the Requirements to allow the job to run.
A machine may be configured to prefer certain jobs over others using the RANK expression. It is an expression, like any other in a machine ClassAd. It can reference any attribute found in either the machine ClassAd or a job ClassAd. The most common use of this expression is likely to configure a machine to prefer to run jobs from the owner of that machine, or by extension, a group of machines to prefer jobs from the owners of those machines.
For example, imagine there is a small research group with 4 machines called tenorsax, piano, bass, and drums. These machines are owned by the 4 users coltrane, tyner, garrison, and jones, respectively.
Assume that there is a large HTCondor pool in the department, and this small research group has spent a lot of money on really fast machines for the group. As part of the larger pool, but to implement a policy that gives priority on the fast machines to anyone in the small research group, set the RANK expression on the machines to reference the Owner attribute and prefer requests where that attribute matches one of the people in the group as in
RANK = Owner == "coltrane" || Owner == "tyner" \
|| Owner == "garrison" || Owner == "jones"
The RANK expression is evaluated as a floating point number. However, like in C, boolean expressions evaluate to either 1 or 0 depending on if they are True or False. So, if this expression evaluated to 1, because the remote job was owned by one of the preferred users, it would be a larger value than any other user for whom the expression would evaluate to 0.
A more complex RANK expression has the same basic set up, where anyone from the group has priority on their fast machines. Its difference is that the machine owner has better priority on their own machine. To set this up for Garrison's machine (bass), place the following entry in the local configuration file of machine bass:
RANK = (Owner == "coltrane") + (Owner == "tyner") \
+ ((Owner == "garrison") * 10) + (Owner == "jones")
Note that the parentheses in this expression are important, because
the + operator has higher default precedence than ==.
The use of + instead of || allows us to distinguish which terms matched and which ones did not. If anyone not in the research group quartet was running a job on the machine called bass, the RANK would evaluate numerically to 0, since none of the boolean terms evaluates to 1, and 0+0+0+0 still equals 0.
Suppose Elvin Jones submits a job. His job would match the bass machine, assuming START evaluated to True for him at that time. The RANK would numerically evaluate to 1. Therefore, the Elvin Jones job could preempt the HTCondor job currently running. Further assume that later Jimmy Garrison submits a job. The RANK evaluates to 10 on machine bass, since the boolean that matches gets multiplied by 10. Due to this, Jimmy Garrison's job could preempt Elvin Jones' job on the bass machine where Jimmy Garrison's jobs are preferred.
The RANK expression is not required to reference the Owner of the jobs. Perhaps there is one machine with an enormous amount of memory, and others with not much at all. Perhaps configure this large-memory machine to prefer to run jobs with larger memory requirements:
RANK = ImageSize
That's all there is to it. The bigger the job, the more this machine wants to run it. It is an altruistic preference, always servicing the largest of jobs, no matter who submitted them. A little less altruistic is the RANK on Coltrane's machine that prefers John Coltrane's jobs over those with the largest Imagesize:
RANK = (Owner == "coltrane" * 1000000000000) + ImagesizeThis RANK does not work if a job is submitted with an image size of more
A machine is assigned a state by HTCondor. The state depends on whether or not the machine is available to run HTCondor jobs, and if so, what point in the negotiations has been reached. The possible states are
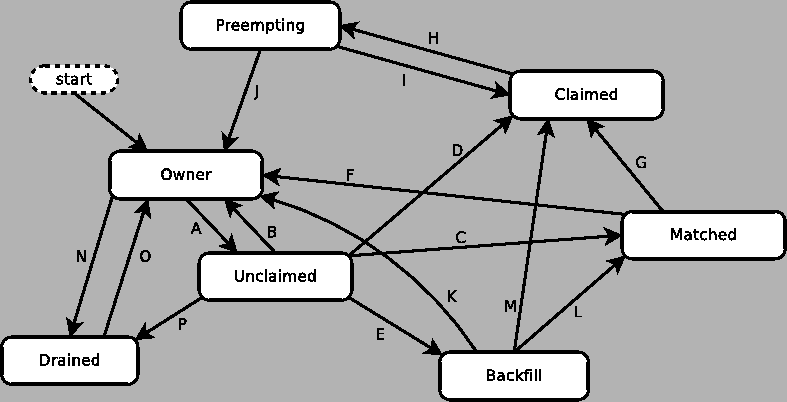
Figure 3.1 shows the states and the possible transitions between the states.
Each transition is labeled with a letter. The cause of each transition is described below.
When a condor_schedd claims a condor_startd, there is a claim lease. So long as the keep alive updates from the condor_schedd to the condor_startd continue to arrive, the lease is reset. If the lease duration passes with no updates, the condor_startd drops the claim and evicts any jobs the condor_schedd sent over.
The alive interval is the amount of time between, or the frequency at which the condor_schedd sends keep alive updates to all condor_schedd daemons. An alive update resets the claim lease at the condor_startd. Updates are UDP packets.
Initially, as when the condor_schedd starts up, the alive interval starts at the value set by the configuration variable ALIVE_INTERVAL. It may be modified when a job is started. The job's ClassAd attribute JobLeaseDuration is checked. If the value of JobLeaseDuration/3 is less than the current alive interval, then the alive interval is set to either this lower value or the imposed lowest limit on the alive interval of 10 seconds. Thus, the alive interval starts at ALIVE_INTERVAL and goes down, never up.
If a claim lease expires, the condor_startd will drop the claim. The length of the claim lease is the job's ClassAd attribute JobLeaseDuration. JobLeaseDuration defaults to 40 minutes time, except when explicitly set within the job's submit description file. If JobLeaseDuration is explicitly set to 0, or it is not set as may be the case for a Web Services job that does not define the attribute, then JobLeaseDuration is given the Undefined value. Further, when undefined, the claim lease duration is calculated with MAX_CLAIM_ALIVES_MISSED * alive interval. The alive interval is the current value, as sent by the condor_schedd. If the condor_schedd reduces the current alive interval, it does not update the condor_startd.
Within some machine states, activities of the machine are defined. The state has meaning regardless of activity. Differences between activities are significant. Therefore, a ``state/activity'' pair describes a machine. The following list describes all the possible state/activity pairs.
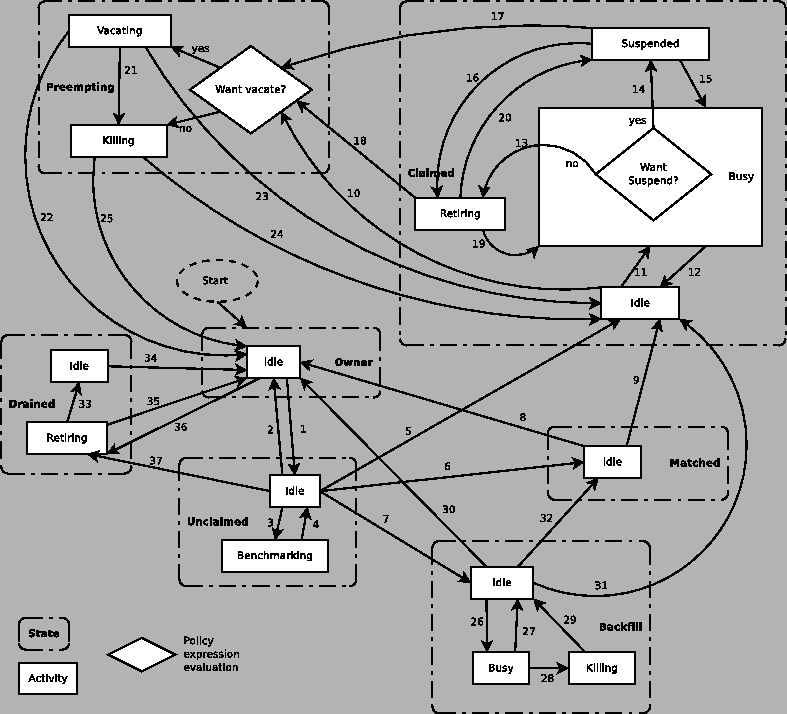
Figure 3.2 on
page ![[*]](crossref.png) gives the overall view of all
machine states and activities and shows the possible transitions
from one to another within the HTCondor system.
Each transition is labeled with a number on the diagram, and
transition numbers referred to in this manual will be bold.
gives the overall view of all
machine states and activities and shows the possible transitions
from one to another within the HTCondor system.
Each transition is labeled with a number on the diagram, and
transition numbers referred to in this manual will be bold.
Various expressions are used to determine when and if many of these state and activity transitions occur. Other transitions are initiated by parts of the HTCondor protocol (such as when the condor_negotiator matches a machine with a schedd). The following section describes the conditions that lead to the various state and activity transitions.
This section traces through all possible state and activity transitions within a machine and describes the conditions under which each one occurs. Whenever a transition occurs, HTCondor records when the machine entered its new activity and/or new state. These times are often used to write expressions that determine when further transitions occurred. For example, enter the Killing activity if a machine has been in the Vacating activity longer than a specified amount of time.
When the startd is first spawned, the machine it represents enters the Owner state. The machine remains in the Owner state while the expression IS_OWNER evaluates to TRUE. If the IS_OWNER expression evaluates to FALSE, then the machine transitions to the Unclaimed state. The default value of IS_OWNER is FALSE, which is intended for dedicated resources. But when the POLICY : Desktop configuration template is used, the IS_OWNER expression is optimized for a shared resource
START =?= FALSESo, the machine will remain in the Owner state as long as the START expression locally evaluates to FALSE. Section 3.7.1 provides more detail on the START expression. If the START locally evaluates to TRUE or cannot be locally evaluated (it evaluates to UNDEFINED), transition 1 occurs and the machine enters the Unclaimed state. The IS_OWNER expression is locally evaluated by the machine, and should not reference job ClassAd attributes, which would be UNDEFINED.
The Owner state represents a resource that is in use by its interactive owner (for example, if the keyboard is being used). The Unclaimed state represents a resource that is neither in use by its interactive user, nor the HTCondor system. From HTCondor's point of view, there is little difference between the Owner and Unclaimed states. In both cases, the resource is not currently in use by the HTCondor system. However, if a job matches the resource's START expression, the resource is available to run a job, regardless of if it is in the Owner or Unclaimed state. The only differences between the two states are how the resource shows up in condor_status and other reporting tools, and the fact that HTCondor will not run benchmarking on a resource in the Owner state. As long as the IS_OWNER expression is TRUE, the machine is in the Owner State. When the IS_OWNER expression is FALSE, the machine goes into the Unclaimed State.
Here is an example that assumes that the POLICY : Desktop configuration template is in use. If the START expression is
START = KeyboardIdle > 15 * $(MINUTE) && Owner == "coltrane"and if KeyboardIdle is 34 seconds, then the machine would remain in the Owner state. Owner is undefined, and
anything && FALSE is FALSE.
If, however, the START expression is
START = KeyboardIdle > 15 * $(MINUTE) || Owner == "coltrane"
and KeyboardIdle is 34 seconds, then the machine
leaves the Owner state and becomes Unclaimed.
This is because
FALSE || UNDEFINED is UNDEFINED.
So, while this machine is not available to just anybody,
if user coltrane has jobs submitted, the machine is willing to run them.
Any other user's jobs have to wait
until KeyboardIdle exceeds 15 minutes.
However, since coltrane might claim this resource,
but has not yet, the machine goes to the Unclaimed state.
While in the Owner state, the startd polls the status of the machine every UPDATE_INTERVAL to see if anything has changed that would lead it to a different state. This minimizes the impact on the Owner while the Owner is using the machine. Frequently waking up, computing load averages, checking the access times on files, computing free swap space take time, and there is nothing time critical that the startd needs to be sure to notice as soon as it happens. If the START expression evaluates to TRUE and five minutes pass before the startd notices, that's a drop in the bucket of high-throughput computing.
The machine can only transition to the Unclaimed state from the Owner state. It does so when the IS_OWNER expression no longer evaluates to TRUE. With the POLICY : Desktop configuration template, that happens when START no longer locally evaluates to FALSE.
Whenever the machine is not actively running a job, it will transition back to the Owner state if IS_OWNER evaluates to TRUE. Once a job is started, the value of IS_OWNER does not matter; the job either runs to completion or is preempted. Therefore, you must configure the preemption policy if you want to transition back to the Owner state from Claimed Busy.
If draining of the machine is initiated while in the Owner state, the slot transitions to Drained/Retiring (transition 36).
If the IS_OWNER expression becomes TRUE, then the machine returns to the Owner state. If the IS_OWNER expression becomes FALSE, then the machine remains in the Unclaimed state. The default value of IS_OWNER is FALSE (never enter Owner state). If the POLICY : Desktop configuration template is used, then the IS_OWNER expression is changed to
START =?= FALSEso that while in the Unclaimed state, if the START expression locally evaluates to FALSE, the machine returns to the Owner state by transition 2.
When in the Unclaimed state, the RUNBENCHMARKS expression is relevant. If RUNBENCHMARKS evaluates to TRUE while the machine is in the Unclaimed state, then the machine will transition from the Idle activity to the Benchmarking activity (transition 3) and perform benchmarks to determine MIPS and KFLOPS. When the benchmarks complete, the machine returns to the Idle activity (transition 4).
The startd automatically inserts an attribute, LastBenchmark, whenever it runs benchmarks, so commonly RunBenchmarks is defined in terms of this attribute, for example:
RunBenchmarks = (time() - LastBenchmark) >= (4 * $(HOUR))
This macro calculates the time since the last benchmark,
so when this time exceeds 4 hours, we run the benchmarks again.
The startd keeps a weighted average of these benchmarking
results to try to get the most accurate numbers possible.
This is why
it is desirable for
the startd to run them more than once in its lifetime.
NOTE: LastBenchmark is initialized to 0 before benchmarks have ever been run. To have the condor_startd run benchmarks as soon as the machine is Unclaimed (if it has not done so already), include a term using LastBenchmark as in the example above.
NOTE: If RUNBENCHMARKS is defined and set to something other than FALSE, the startd will automatically run one set of benchmarks when it first starts up. To disable benchmarks, both at startup and at any time thereafter, set RUNBENCHMARKS to FALSE or comment it out of the configuration file.
From the Unclaimed state, the machine can go to four other possible states: Owner (transition 2), Backfill/Idle, Matched, or Claimed/Idle.
Once the condor_negotiator matches an Unclaimed machine with a requester at a given schedd, the negotiator sends a command to both parties, notifying them of the match. If the schedd receives that notification and initiates the claiming procedure with the machine before the negotiator's message gets to the machine, the Match state is skipped, and the machine goes directly to the Claimed/Idle state (transition 5). However, normally the machine will enter the Matched state (transition 6), even if it is only for a brief period of time.
If the machine has been configured to perform backfill jobs (see section 3.14.10), while it is in Unclaimed/Idle it will evaluate the START_BACKFILL expression. Once START_BACKFILL evaluates to TRUE, the machine will enter the Backfill/Idle state (transition 7) to begin the process of running backfill jobs.
If draining of the machine is initiated while in the Unclaimed state, the slot transitions to Drained/Retiring (transition 37).
The Matched state is not very interesting to HTCondor. Noteworthy in this state is that the machine lies about its START expression while in this state and says that Requirements are False to prevent being matched again before it has been claimed. Also interesting is that the startd starts a timer to make sure it does not stay in the Matched state too long. The timer is set with the MATCH_TIMEOUT configuration file macro. It is specified in seconds and defaults to 120 (2 minutes). If the schedd that was matched with this machine does not claim it within this period of time, the machine gives up, and goes back into the Owner state via transition 8. It will probably leave the Owner state right away for the Unclaimed state again and wait for another match.
At any time while the machine is in the Matched state, if the START expression locally evaluates to FALSE, the machine enters the Owner state directly (transition 8).
If the schedd that was matched with the machine claims it before the MATCH_TIMEOUT expires, the machine goes into the Claimed/Idle state (transition 9).
The Claimed state is certainly the most complex state. It has the most possible activities and the most expressions that determine its next activities. In addition, the condor_checkpoint and condor_vacate commands affect the machine when it is in the Claimed state. In general, there are two sets of expressions that might take effect. They depend on the universe of the request: standard or vanilla. The standard universe expressions are the normal expressions. For example:
WANT_SUSPEND = True
WANT_VACATE = $(ActivationTimer) > 10 * $(MINUTE)
SUSPEND = $(KeyboardBusy) || $(CPUBusy)
...
The vanilla expressions have the string``_VANILLA'' appended to their names. For example:
WANT_SUSPEND_VANILLA = True
WANT_VACATE_VANILLA = True
SUSPEND_VANILLA = $(KeyboardBusy) || $(CPUBusy)
...
Without specific vanilla versions, the normal versions will be used for all jobs, including vanilla jobs. In this manual, the normal expressions are referenced. The difference exists for the the resource owner that might want the machine to behave differently for vanilla jobs, since they cannot checkpoint. For example, owners may want vanilla jobs to remain suspended for longer than standard jobs.
While Claimed, the POLLING_INTERVAL takes effect, and the startd polls the machine much more frequently to evaluate its state.
If the machine owner starts typing on the console again, it is best to notice this as soon as possible to be able to start doing whatever the machine owner wants at that point. For multi-core machines, if any slot is in the Claimed state, the startd polls the machine frequently. If already polling one slot, it does not cost much to evaluate the state of all the slots at the same time.
There are a variety of events that may cause the startd to try to get rid of or temporarily suspend a running job. Activity on the machine's console, load from other jobs, or shutdown of the startd via an administrative command are all possible sources of interference. Another one is the appearance of a higher priority claim to the machine by a different HTCondor user.
Depending on the configuration, the startd may respond quite
differently to activity on the machine, such as keyboard activity or
demand for the cpu from processes that are not managed by HTCondor. The
startd can be configured to completely ignore such activity or to
suspend the job or even to kill it. A standard configuration for a desktop
machine might be to go through
successive levels of getting the job out of the way.
The first and least costly to the job is suspending it.
This works for both standard and vanilla jobs.
If suspending the job for a short while does not satisfy the machine
owner (the owner is still using the machine after a specific period of
time), the startd moves on to vacating the job.
Vacating a standard universe job
involves performing a checkpoint so that the work already completed
is not lost. Vanilla jobs are sent a soft kill signal so that they
can gracefully shut down if necessary; the default is SIGTERM.
If vacating does not satisfy the machine owner (usually because it is
taking too long and the owner wants their machine back now),
the final, most drastic stage is reached: killing.
Killing is a quick death to the job, using a hard-kill signal that cannot
be intercepted by the application. For vanilla jobs that do no special
signal handling, vacating and killing are equivalent.
The WANT_SUSPEND expression determines if the machine will evaluate the SUSPEND expression to consider entering the Suspended activity. The WANT_VACATE expression determines what happens when the machine enters the Preempting state. It will go to the Vacating activity or directly to Killing. If one or both of these expressions evaluates to FALSE, the machine will skip that stage of getting rid of the job and proceed directly to the more drastic stages.
When the machine first enters the Claimed state, it goes to the Idle activity. From there, it has two options. It can enter the Preempting state via transition 10 (if a condor_vacate arrives, or if the START expression locally evaluates to FALSE), or it can enter the Busy activity (transition 11) if the schedd that has claimed the machine decides to activate the claim and start a job.
From Claimed/Busy, the machine can transition to three other state/activity pairs. The startd evaluates the WANT_SUSPEND expression to decide which other expressions to evaluate. If WANT_SUSPEND is TRUE, then the startd evaluates the SUSPEND expression. If WANT_SUSPEND is any value other than TRUE, then the startd will evaluate the PREEMPT expression and skip the Suspended activity entirely. By transition, the possible state/activity destinations from Claimed/Busy:
Another reason the machine would go from Claimed/Busy to Claimed/Retiring is if the condor_negotiator matched the machine with a ``better'' match. This better match could either be from the machine's perspective using the startd RANK expression, or it could be from the negotiator's perspective due to a job with a higher user priority.
Another case resulting in a transition to Claimed/Retiring is when the startd is being shut down. The only exception is a ``fast'' shutdown, which bypasses retirement completely.
If a condor_checkpoint command arrives, or the PERIODIC_CHECKPOINT expression evaluates to TRUE, there is no state change. The startd has no way of knowing when this process completes, so periodic checkpointing can not be another state. Periodic checkpointing remains in the Claimed/Busy state and appears as a running job.
From the Claimed/Suspended state, the following transitions may occur:
For the Claimed/Retiring state, the following transitions may occur:
The Preempting state is less complex than the Claimed state. There are two activities. Depending on the value of WANT_VACATE, a machine will be in the Vacating activity (if True) or the Killing activity (if False).
While in the Preempting state (regardless of activity) the machine advertises its Requirements expression as False to signify that it is not available for further matches, either because it is about to transition to the Owner state, or because it has already been matched with one preempting match, and further preempting matches are disallowed until the machine has been claimed by the new match.
The main function of the Preempting state is to get rid of the condor_starter associated with the resource. If the condor_starter associated with a given claim exits while the machine is still in the Vacating activity, then the job successfully completed a graceful shutdown. For standard universe jobs, this means that a checkpoint was saved. For other jobs, this means the application was given an opportunity to do a graceful shutdown, by intercepting the soft kill signal.
If the machine is in the Vacating activity, it keeps evaluating the KILL expression. As soon as this expression evaluates to TRUE, the machine enters the Killing activity (transition 21). If the Vacating activity lasts for as long as the maximum vacating time, then the machine also enters the Killing activity. The maximum vacating time is determined by the configuration variable MachineMaxVacateTime. This may be adjusted by the setting of the job ClassAd attribute JobMaxVacateTime.
When the starter exits, or if there was no starter running when the machine enters the Preempting state (transition 10), the other purpose of the Preempting state is completed: notifying the schedd that had claimed this machine that the claim is broken.
At this point, the machine enters either the Owner state by transition 22 (if the job was preempted because the machine owner came back) or the Claimed/Idle state by transition 23 (if the job was preempted because a better match was found).
If the machine enters the Killing activity, (because either WANT_VACATE was False or the KILL expression evaluated to True), it attempts to force the condor_starter to immediately kill the underlying HTCondor job. Once the machine has begun to hard kill the HTCondor job, the condor_startd starts a timer, the length of which is defined by the KILLING_TIMEOUT 3.5.8 macro. This macro is defined in seconds and defaults to 30. If this timer expires and the machine is still in the Killing activity, something has gone seriously wrong with the condor_starter and the startd tries to vacate the job immediately by sending SIGKILL to all of the condor_starter's children, and then to the condor_starter itself.
Once the condor_starter has killed off all the processes associated with the job and exited, and once the schedd that had claimed the machine is notified that the claim is broken, the machine will leave the Preempting/Killing state. If the job was preempted because a better match was found, the machine will enter Claimed/Idle (transition 24). If the preemption was caused by the machine owner (the PREEMPT expression evaluated to TRUE, condor_vacate was used, etc), the machine will enter the Owner state (transition 25).
The Backfill state is used whenever the machine is performing low
priority background tasks to keep itself busy.
For more information about backfill support in HTCondor, see
section 3.14.10 on page .
This state is only used if the machine has been configured to enable
backfill computation, if a specific backfill manager has been
installed and configured, and if the machine is otherwise idle (not
being used interactively or for regular HTCondor computations).
If the machine meets all these requirements, and the
START_BACKFILL expression evaluates to TRUE, the machine will
move from the Unclaimed/Idle state to Backfill/Idle (transition
7).
Once a machine is in Backfill/Idle, it will immediately attempt to spawn whatever backfill manager it has been configured to use (currently, only the BOINC client is supported as a backfill manager in HTCondor). Once the BOINC client is running, the machine will enter Backfill/Busy (transition 26) to indicate that it is now performing a backfill computation.
NOTE: On multi-core machines, the condor_startd will only spawn a single instance of the BOINC client, even if multiple slots are available to run backfill jobs. Therefore, only the first machine to enter Backfill/Idle will cause a copy of the BOINC client to start running. If a given slot on a multi-core enters the Backfill state and a BOINC client is already running under this condor_startd, the slot will immediately enter Backfill/Busy without waiting to spawn another copy of the BOINC client.
If the BOINC client ever exits on its own (which normally wouldn't happen), the machine will go back to Backfill/Idle (transition 27) where it will immediately attempt to respawn the BOINC client (and return to Backfill/Busy via transition 26).
As the BOINC client is running a backfill computation, a number of events can occur that will drive the machine out of the Backfill state. The machine can get matched or claimed for an HTCondor job, interactive users can start using the machine again, the machine might be evicted with condor_vacate, or the condor_startd might be shutdown. All of these events cause the condor_startd to kill the BOINC client and all its descendants, and enter the Backfill/Killing state (transition 28).
Once the BOINC client and all its children have exited the system, the machine will enter the Backfill/Idle state to indicate that the BOINC client is now gone (transition 29). As soon as it enters Backfill/Idle after the BOINC client exits, the machine will go into another state, depending on what caused the BOINC client to be killed in the first place.
If the EVICT_BACKFILL expression evaluates to TRUE while a machine is in Backfill/Busy, after the BOINC client is gone, the machine will go back into the Owner/Idle state (transition 30). The machine will also return to the Owner/Idle state after the BOINC client exits if condor_vacate was used, or if the condor_startd is being shutdown.
When a machine running backfill jobs is matched with a requester that wants to run an HTCondor job, the machine will either enter the Matched state, or go directly into Claimed/Idle. As with the case of a machine in Unclaimed/Idle (described above), the condor_negotiator informs both the condor_startd and the condor_schedd of the match, and the exact state transitions at the machine depend on what order the various entities initiate communication with each other. If the condor_schedd is notified of the match and sends a request to claim the condor_startd before the condor_negotiator has a chance to notify the condor_startd, once the BOINC client exits, the machine will immediately enter Claimed/Idle (transition 31). Normally, the notification from the condor_negotiator will reach the condor_startd before the condor_schedd attempts to claim it. In this case, once the BOINC client exits, the machine will enter Matched/Idle (transition 32).
The Drained state is used when the machine is being drained, for example by condor_drain or by the condor_defrag daemon, and the slot has finished running jobs and is no longer willing to run new jobs.
Slots initially enter the Drained/Retiring state. Once all slots have been drained, the slots transition to the Idle activity (transition 33).
If draining is finalized or canceled, the slot transitions to Owner/Idle (transitions 34 and 35).
The machine enters the Preempting state with the goal of finishing shutting down the job by the end of the retirement time. If the job vacating policy grants the job X seconds of vacating time, the transition to the Preempting state will happen X seconds before the end of the retirement time, so that the hard-killing of the job will not happen until the end of the retirement time, if the job does not finish shutting down before then.
This expression is evaluated in the context of the job ClassAd, so it may refer to attributes of the current job as well as machine attributes.
By default the condor_negotiator will not match jobs to a slot with retirement time remaining. This behavior is controlled by NEGOTIATOR_CONSIDER_EARLY_PREEMPTION.
This section describes various policy configurations, including the default policy.
These settings are the default as shipped with HTCondor. They have been used for many years with no problems. The vanilla expressions are identical to the regular ones. (They are not listed here. If not defined, the standard expressions are used for vanilla jobs as well).
The following are macros to help write the expressions clearly.
These variable definitions exist in the example configuration file in order to help write legible expressions. They are not required, and perhaps will go unused by many configurations.
## These macros are here to help write legible expressions: MINUTE = 60 HOUR = (60 * $(MINUTE)) StateTimer = (time() - EnteredCurrentState) ActivityTimer = (time() - EnteredCurrentActivity) ActivationTimer = (time() - JobStart) LastCkpt = (time() - LastPeriodicCheckpoint) NonCondorLoadAvg = (LoadAvg - CondorLoadAvg) BackgroundLoad = 0.3 HighLoad = 0.5 StartIdleTime = 15 * $(MINUTE) ContinueIdleTime = 5 * $(MINUTE) MaxSuspendTime = 10 * $(MINUTE) KeyboardBusy = KeyboardIdle < $(MINUTE) ConsoleBusy = (ConsoleIdle < $(MINUTE)) CPUIdle = $(NonCondorLoadAvg) <= $(BackgroundLoad) CPUBusy = $(NonCondorLoadAvg) >= $(HighLoad) KeyboardNotBusy = ($(KeyboardBusy) == False) MachineBusy = ($(CPUBusy) || $(KeyboardBusy)
Preemption is disabled as a default. Always desire to start jobs.
WANT_SUSPEND = False WANT_VACATE = False START = True SUSPEND = False CONTINUE = True PREEMPT = False # Kill jobs that take too long leaving gracefully. MachineMaxVacateTime = 10 * $(MINUTE) KILL = False
Periodic checkpointing specifies that for jobs smaller than 60 Mbytes, take a periodic checkpoint every 6 hours. For larger jobs, only take a checkpoint every 12 hours.
PERIODIC_CHECKPOINT = ( (ImageSize < 60000) && \
($(LastCkpt) > (6 * $(HOUR))) ) || \
( $(LastCkpt) > (12 * $(HOUR)) )
At UW-Madison, we have a fast network. We simplify our expression considerably to
PERIODIC_CHECKPOINT = $(LastCkpt) > (3 * $(HOUR))
This example shows how the default macros can be used to set up a machine for running test jobs from a specific user. Suppose we want the machine to behave normally, except if user coltrane submits a job. In that case, we want that job to start regardless of what is happening on the machine. We do not want the job suspended, vacated or killed. This is reasonable if we know coltrane is submitting very short running programs for testing purposes. The jobs should be executed right away. This works with any machine (or the whole pool, for that matter) by adding the following 5 expressions to the existing configuration:
START = ($(START)) || Owner == "coltrane" SUSPEND = ($(SUSPEND)) && Owner != "coltrane" CONTINUE = $(CONTINUE) PREEMPT = ($(PREEMPT)) && Owner != "coltrane" KILL = $(KILL)Notice that there is nothing special in either the CONTINUE or KILL expressions. If Coltrane's jobs never suspend, they never look at CONTINUE. Similarly, if they never preempt, they never look at KILL.
HTCondor can be configured to only run jobs at certain times of the day. In general, we discourage configuring a system like this, since there will often be lots of good cycles on machines, even when their owners say ``I'm always using my machine during the day.'' However, if you submit mostly vanilla jobs or other jobs that cannot produce checkpoints, it might be a good idea to only allow the jobs to run when you know the machines will be idle and when they will not be interrupted.
To configure this kind of policy, use the ClockMin and ClockDay attributes. These are special attributes which are automatically inserted by the condor_startd into its ClassAd, so you can always reference them in your policy expressions. ClockMin defines the number of minutes that have passed since midnight. For example, 8:00am is 8 hours after midnight, or 8 * 60 minutes, or 480. 5:00pm is 17 hours after midnight, or 17 * 60, or 1020. ClockDay defines the day of the week, Sunday = 0, Monday = 1, and so on.
To make the policy expressions easy to read, we recommend using macros to define the time periods when you want jobs to run or not run. For example, assume regular work hours at your site are from 8:00am until 5:00pm, Monday through Friday:
WorkHours = ( (ClockMin >= 480 && ClockMin < 1020) && \
(ClockDay > 0 && ClockDay < 6) )
AfterHours = ( (ClockMin < 480 || ClockMin >= 1020) || \
(ClockDay == 0 || ClockDay == 6) )
Of course, you can fine-tune these settings by changing the definition of AfterHours and WorkHours for your site.
To force HTCondor jobs to stay off of your machines during work hours:
# Only start jobs after hours. START = $(AfterHours) # Consider the machine busy during work hours, or if the keyboard or # CPU are busy. MachineBusy = ( $(WorkHours) || $(CPUBusy) || $(KeyboardBusy) )
This MachineBusy macro is convenient if other than the default SUSPEND and PREEMPT expressions are used.
Suppose you have two classes of machines in your pool: desktop machines and dedicated cluster machines. In this case, you might not want keyboard activity to have any effect on the dedicated machines. For example, when you log into these machines to debug some problem, you probably do not want a running job to suddenly be killed. Desktop machines, on the other hand, should do whatever is necessary to remain responsive to the user.
There are many ways to achieve the desired behavior. One way is to make a standard desktop policy and a standard non-desktop policy and to copy the desired one into the local configuration file for each machine. Another way is to define one standard policy (in the global configuration file) with a simple toggle that can be set in the local configuration file. The following example illustrates the latter approach.
For ease of use, an entire policy is included in this example. Some of the expressions are just the usual default settings.
# If "IsDesktop" is configured, make it an attribute of the machine ClassAd.
STARTD_ATTRS = IsDesktop
# Only consider starting jobs if:
# 1) the load average is low enough OR the machine is currently
# running an HTCondor job
# 2) AND the user is not active (if a desktop)
START = ( ($(CPUIdle) || (State != "Unclaimed" && State != "Owner")) \
&& (IsDesktop =!= True || (KeyboardIdle > $(StartIdleTime))) )
# Suspend (instead of vacating/killing) for the following cases:
WANT_SUSPEND = ( $(SmallJob) || $(JustCpu) \
|| $(IsVanilla) )
# When preempting, vacate (instead of killing) in the following cases:
WANT_VACATE = ( $(ActivationTimer) > 10 * $(MINUTE) \
|| $(IsVanilla) )
# Suspend jobs if:
# 1) The CPU has been busy for more than 2 minutes, AND
# 2) the job has been running for more than 90 seconds
# 3) OR suspend if this is a desktop and the user is active
SUSPEND = ( ((CpuBusyTime > 2 * $(MINUTE)) && ($(ActivationTimer) > 90)) \
|| ( IsDesktop =?= True && $(KeyboardBusy) ) )
# Continue jobs if:
# 1) the CPU is idle, AND
# 2) we've been suspended more than 5 minutes AND
# 3) the keyboard has been idle for long enough (if this is a desktop)
CONTINUE = ( $(CPUIdle) && ($(ActivityTimer) > 300) \
&& (IsDesktop =!= True || (KeyboardIdle > $(ContinueIdleTime))) )
# Preempt jobs if:
# 1) The job is suspended and has been suspended longer than we want
# 2) OR, we don't want to suspend this job, but the conditions to
# suspend jobs have been met (someone is using the machine)
PREEMPT = ( ((Activity == "Suspended") && \
($(ActivityTimer) > $(MaxSuspendTime))) \
|| (SUSPEND && (WANT_SUSPEND == False)) )
# Replace 0 in the following expression with whatever amount of
# retirement time you want dedicated machines to provide. The other part
# of the expression forces the whole expression to 0 on desktop
# machines.
MAXJOBRETIREMENTTIME = (IsDesktop =!= True) * 0
# Kill jobs if they have taken too long to vacate gracefully
MachineMaxVacateTime = 10 * $(MINUTE)
KILL = False
With this policy in the global configuration, the local configuration files for desktops can be easily configured with the following line:
IsDesktop = True
In all other cases, the default policy described above will ignore keyboard activity.
Preemption causes a running job to be suspended or killed, such that another job can run. As of HTCondor version 8.1.5, preemption is disabled by the default configuration. Previous versions of HTCondor had configuration that enabled preemption. Upon upgrade, the previous behavior will continue, if the previous configuration files are used. New configuration file examples disable preemption, but contain directions for enabling preemption.
The implementation of this policy utilizes two categories of slots, identified as suspendable or nonsuspendable. A job identifies which category of slot it wishes to run on. This affects two aspects of the policy:
# Lie to HTCondor, to achieve 2 slots for each real slot
NUM_CPUS = $(DETECTED_CORES)*2
# There is no good way to tell HTCondor that the two slots should be treated
# as though they share the same real memory, so lie about how much
# memory we have.
MEMORY = $(DETECTED_MEMORY)*2
# Slots 1 through DETECTED_CORES are nonsuspendable and the rest are
# suspendable
IsSuspendableSlot = SlotID > $(DETECTED_CORES)
# If I am a suspendable slot, my corresponding nonsuspendable slot is
# my SlotID plus $(DETECTED_CORES)
NonSuspendableSlotState = eval(strcat("slot",SlotID-$(DETECTED_CORES),"_State")
# The above expression looks at slotX_State, so we need to add
# State to the list of slot attributes to advertise.
STARTD_SLOT_ATTRS = $(STARTD_SLOT_ATTRS) State
# For convenience, advertise these expressions in the machine ad.
STARTD_ATTRS = $(STARTD_ATTRS) IsSuspendableSlot NonSuspendableSlotState
MyNonSuspendableSlotIsIdle = \
(NonSuspendableSlotState =!= "Claimed" && NonSuspendableSlotState =!= "Preempting")
# NonSuspendable slots are always willing to start jobs.
# Suspendable slots are only willing to start if the NonSuspendable slot is idle.
START = \
IsSuspendableSlot!=True && IsSuspendableJob=!=True || \
IsSuspendableSlot && IsSuspendableJob==True && $(MyNonSuspendableSlotIsIdle)
# Suspend the suspendable slot if the other slot is busy.
SUSPEND = \
IsSuspendableSlot && $(MyNonSuspendableSlotIsIdle)!=True
WANT_SUSPEND = $(SUSPEND)
CONTINUE = ($(SUSPEND)) != True
Note that in this example, the job ClassAd attribute IsSuspendableJob has no special meaning to HTCondor. It is an invented name chosen for this example. To take advantage of the policy, a job that wishes to be suspended must submit the job so that this attribute is defined. The following line should be placed in the job's submit description file:
+IsSuspendableJob = True
Policy may be set based on whether a job is an interactive one or not. Each interactive job has the job ClassAd attribute
InteractiveJob = Trueand this may be used to identify interactive jobs, distinguishing them from all other jobs.
As an example, presume that slot 1 prefers interactive jobs. Set the machine's RANK to show the preference:
RANK = ( (MY.SlotID == 1) && (TARGET.InteractiveJob =?= True) )
Or, if slot 1 should be reserved for interactive jobs:
START = ( (MY.SlotID == 1) && (TARGET.InteractiveJob =?= True) )
Machines with more than one CPU or core may be configured to run more than one job at a time. As always, owners of the resources have great flexibility in defining the policy under which multiple jobs may run, suspend, vacate, etc.
Multi-core machines are represented to the HTCondor system as shared resources broken up into individual slots. Each slot can be matched and claimed by users for jobs. Each slot is represented by an individual machine ClassAd. In this way, each multi-core machine will appear to the HTCondor system as a collection of separate slots. As an example, a multi-core machine named vulture.cs.wisc.edu would appear to HTCondor as the multiple machines, named slot1@vulture.cs.wisc.edu, slot2@vulture.cs.wisc.edu, slot3@vulture.cs.wisc.edu, and so on.
The way that the condor_startd breaks up the shared system resources into the different slots is configurable. All shared system resources, such as RAM, disk space, and swap space, can be divided evenly among all the slots, with each slot assigned one core. Alternatively, slot types are defined by configuration, so that resources can be unevenly divided. Regardless of the scheme used, it is important to remember that the goal is to create a representative slot ClassAd, to be used for matchmaking with jobs.
HTCondor does not directly enforce slot shared resource allocations, and jobs are free to oversubscribe to shared resources. Consider an example where two slots are each defined with 50% of available RAM. The resultant ClassAd for each slot will advertise one half the available RAM. Users may submit jobs with RAM requirements that match these slots. However, jobs run on either slot are free to consume more than 50% of available RAM. HTCondor will not directly enforce a RAM utilization limit on either slot. If a shared resource enforcement capability is needed, it is possible to write a policy that will evict a job that oversubscribes to shared resources, as described in section 3.7.1.
Within a machine the shared system resources of cores, RAM, swap space and disk space will be divided for use by the slots. There are two main ways to go about dividing the resources of a multi-core machine:
How many slots are reported at a time is accomplished by setting the configuration variable NUM_SLOTS to the integer number of slots desired. If variable NUM_SLOTS is not defined, it defaults to the number of cores within the machine. Variable NUM_SLOTS may not be used to make HTCondor advertise more slots than there are cores on the machine. The number of cores is defined by NUM_CPUS.
Configuration variables define the slot types, as well as variables that list how much of each system resource goes to each slot type.
Configuration variable SLOT_TYPE_<N>,
where <N> is an integer
(for example, SLOT_TYPE_1)
defines the slot type.
Note that there may be multiple slots of each type.
The number of slots created of a given type
is configured with NUM_SLOTS_TYPE_<N>.
The type can be defined by:
The number of CPUs and the total amount of RAM in the machine do not change over time. For these attributes, specify either absolute values or percentages of the total available amount (or auto). For example, in a machine with 128 Mbytes of RAM, all the following definitions result in the same allocation amount.
SLOT_TYPE_1 = mem=64 SLOT_TYPE_1 = mem=1/2 SLOT_TYPE_1 = mem=50% SLOT_TYPE_1 = mem=auto
Amounts of disk space and swap space are dynamic, as they change over time. For these, specify a percentage or fraction of the total value that is allocated to each slot, instead of specifying absolute values. As the total values of these resources change on the machine, each slot will take its fraction of the total and report that as its available amount.
The disk space allocated to each slot is taken from the disk partition containing the slot's EXECUTE or SLOT<N>_EXECUTE directory. If every slot is in a different partition, then each one may be defined with up to 100% for its disk share. If some slots are in the same partition, then their total is not allowed to exceed 100%.
The four predefined attribute names are case insensitive when defining slot types. The first letter of the attribute name distinguishes between these attributes. The four attributes, with several examples of acceptable names for each:
As an example, consider a machine with 4 cores and 256 Mbytes of RAM. Here are valid example slot type definitions. Types 1-3 are all equivalent to each other, as are types 4-6. Note that in a real configuration, all of these slot types would not be used together, because they add up to more than 100% of the various system resources. This configuration example also omits definitions of NUM_SLOTS_TYPE_<N>, to define the number of each slot type.
SLOT_TYPE_1 = cpus=2, ram=128, swap=25%, disk=1/2 SLOT_TYPE_2 = cpus=1/2, memory=128, virt=25%, disk=50% SLOT_TYPE_3 = c=1/2, m=50%, v=1/4, disk=1/2 SLOT_TYPE_4 = c=25%, m=64, v=1/4, d=25% SLOT_TYPE_5 = 25% SLOT_TYPE_6 = 1/4
The default value for each resource share is auto. The share may also be explicitly set to auto. All slots with the value auto for a given type of resource will evenly divide whatever remains, after subtracting out explicitly allocated resources given in other slot definitions. For example, if one slot is defined to use 10% of the memory and the rest define it as auto (or leave it undefined), then the rest of the slots will evenly divide 90% of the memory between themselves.
In both of the following examples, the disk share is set to auto, number of cores is 1, and everything else is 50%:
SLOT_TYPE_1 = cpus=1, ram=1/2, swap=50% SLOT_TYPE_1 = cpus=1, disk=auto, 50%
Note that it is possible to set the configuration variables such that they specify an impossible configuration. If this occurs, the condor_startd daemon fails after writing a message to its log attempting to indicate the configuration requirements that it could not implement.
In addition to the standard resources of CPUs, memory, disk, and swap, the administrator may also define custom resources on a localized per-machine basis.
The resource names and quantities of available resources are defined using configuration variables of the form MACHINE_RESOURCE_<name>, as shown in this example:
MACHINE_RESOURCE_gpu = 16 MACHINE_RESOURCE_actuator = 8
If the configuration uses the optional configuration variable MACHINE_RESOURCE_NAMES to enable and disable local machine resources, also add the resource names to this variable. For example:
if defined MACHINE_RESOURCE_NAMES MACHINE_RESOURCE_NAMES = $(MACHINE_RESOURCE_NAMES) gpu actuator endif
Local machine resource names defined in this way may now be used in conjunction with SLOT_TYPE_<N>, using all the same syntax described earlier in this section. The following example demonstrates the definition of static and partitionable slot types with local machine resources:
# declare one partitionable slot with half of the GPUs, 6 actuators, and # 50% of all other resources: SLOT_TYPE_1 = gpu=50%,actuator=6,50% SLOT_TYPE_1_PARTITIONABLE = TRUE NUM_SLOTS_TYPE_1 = 1 # declare two static slots, each with 25% of the GPUs, 1 actuator, and # 25% of all other resources: SLOT_TYPE_2 = gpu=25%,actuator=1,25% SLOT_TYPE_2_PARTITIONABLE = FALSE NUM_SLOTS_TYPE_2 = 2
A job may request these local machine resources using the syntax request_<name>, as described in section 3.7.1. This example shows a portion of a submit description file that requests GPUs and an actuator:
universe = vanilla # request two GPUs and one actuator: request_gpu = 2 request_actuator = 1 queue
The slot ClassAd will represent each local machine resource with the following attributes:
From the example given, the gpu resource would be represented by the ClassAd attributes TotalGpu, DetectedGpu, TotalSlotGpu, and Gpu. In the job ClassAd, the amount of the requested machine resource appears in a job ClassAd attribute named Request<name>. For this example, the two attributes will be RequestGpu and RequestActuator.
The number of each type being reported can be changed at run time, by issuing a reconfiguration command to the condor_startd daemon (sending a SIGHUP or using condor_reconfig). However, the definitions for the types themselves cannot be changed with reconfiguration. To change any slot type definitions, use condor_restart
condor_restart -startdfor that change to take effect.
Each slot within a multi-core machine is treated as an independent machine, each with its own view of its state as represented by the machine ClassAd attribute State. The policy expressions for the multi-core machine as a whole are propagated from the condor_startd to the slot's machine ClassAd. This policy may consider a slot state(s) in its expressions. This makes some policies easy to set, but it makes other policies difficult or impossible to set.
An easy policy to set configures how many of the slots notice console or tty activity on the multi-core machine as a whole. Slots that are not configured to notice any activity will report ConsoleIdle and KeyboardIdle times from when the condor_startd daemon was started, plus a configurable number of seconds. A multi-core machine with the default policy settings can add the keyboard and console to be noticed by only one slot. Assuming a reasonable load average, only the one slot will suspend or vacate its job when the owner starts typing at their machine again. The rest of the slots could be matched with jobs and continue running them, even while the user was interactively using the machine. If the default policy is used, all slots notice tty and console activity and currently running jobs would suspend.
This example policy is controlled with the following configuration variables.
Each slot has its own machine ClassAd. Yet, the policy expressions for the multi-core machine are propagated and inherited from configuration of the condor_startd. Therefore, the policy expressions for each slot are the same. This makes the implementation of certain types of policies impossible, because while evaluating the state of one slot within the multi-core machine, the state of other slots are not available. Decisions for one slot cannot be based on what other slots are doing.
Specifically, the evaluation of a slot policy expression works in the following way.
To set a different policy for the slots within a machine, incorporate the slot-specific machine ClassAd attribute SlotID. A SUSPEND policy that is different for each of the two slots will be of the form
SUSPEND = ( (SlotID == 1) && (PolicyForSlot1) ) || \
( (SlotID == 2) && (PolicyForSlot2) )
where (PolicyForSlot1) and (PolicyForSlot2) are the
desired expressions for each slot.
Most operating systems define the load average for a multi-core machine as the total load on all cores. For example, a 4-core machine with 3 CPU-bound processes running at the same time will have a load of 3.0. In HTCondor, we maintain this view of the total load average and publish it in all resource ClassAds as TotalLoadAvg.
HTCondor also provides a per-core load average for multi-core machines. This nicely represents the model that each node on a multi-core machine is a slot, separate from the other nodes. All of the default, single-core policy expressions can be used directly on multi-core machines, without modification, since the LoadAvg and CondorLoadAvg attributes are the per-slot versions, not the total, multi-core wide versions.
The per-core load average on multi-core machines is an HTCondor invention. No system call exists to ask the operating system for this value. HTCondor already computes the load average generated by HTCondor on each slot. It does this by close monitoring of all processes spawned by any of the HTCondor daemons, even ones that are orphaned and then inherited by init. This HTCondor load average per slot is reported as the attribute CondorLoadAvg in all resource ClassAds, and the total HTCondor load average for the entire machine is reported as TotalCondorLoadAvg. The total, system-wide load average for the entire machine is reported as TotalLoadAvg. Basically, HTCondor walks through all the slots and assigns out portions of the total load average to each one. First, HTCondor assigns the known HTCondor load average to each node that is generating load. If there is any load average left in the total system load, it is considered an owner load. Any slots HTCondor believes are in the Owner state, such as ones that have keyboard activity, are the first to get assigned this owner load. HTCondor hands out owner load in increments of at most 1.0, so generally speaking, no slot has a load average above 1.0. If HTCondor runs out of total load average before it runs out of slots, all the remaining machines believe that they have no load average at all. If, instead, HTCondor runs out of slots and it still has owner load remaining, HTCondor starts assigning that load to HTCondor nodes as well, giving individual nodes with a load average higher than 1.0.
This section describes how the condor_startd daemon handles its debugging messages for multi-core machines. In general, a given log message will either be something that is machine-wide, such as reporting the total system load average, or it will be specific to a given slot. Any log entries specific to a slot have an extra word printed out in the entry with the slot number. So, for example, here's the output about system resources that are being gathered (with D_FULLDEBUG and D_LOAD turned on) on a 2-core machine with no HTCondor activity, and the keyboard connected to both slots:
11/25 18:15 Swap space: 131064 11/25 18:15 number of Kbytes available for (/home/condor/execute): 1345063 11/25 18:15 Looking up RESERVED_DISK parameter 11/25 18:15 Reserving 5120 Kbytes for file system 11/25 18:15 Disk space: 1339943 11/25 18:15 Load avg: 0.340000 0.800000 1.170000 11/25 18:15 Idle Time: user= 0 , console= 4 seconds 11/25 18:15 SystemLoad: 0.340 TotalCondorLoad: 0.000 TotalOwnerLoad: 0.340 11/25 18:15 slot1: Idle time: Keyboard: 0 Console: 4 11/25 18:15 slot1: SystemLoad: 0.340 CondorLoad: 0.000 OwnerLoad: 0.340 11/25 18:15 slot2: Idle time: Keyboard: 0 Console: 4 11/25 18:15 slot2: SystemLoad: 0.000 CondorLoad: 0.000 OwnerLoad: 0.000 11/25 18:15 slot1: State: Owner Activity: Idle 11/25 18:15 slot2: State: Owner Activity: Idle
If, on the other hand, this machine only had one slot connected to the keyboard and console, and the other slot was running a job, it might look something like this:
11/25 18:19 Load avg: 1.250000 0.910000 1.090000 11/25 18:19 Idle Time: user= 0 , console= 0 seconds 11/25 18:19 SystemLoad: 1.250 TotalCondorLoad: 0.996 TotalOwnerLoad: 0.254 11/25 18:19 slot1: Idle time: Keyboard: 0 Console: 0 11/25 18:19 slot1: SystemLoad: 0.254 CondorLoad: 0.000 OwnerLoad: 0.254 11/25 18:19 slot2: Idle time: Keyboard: 1496 Console: 1496 11/25 18:19 slot2: SystemLoad: 0.996 CondorLoad: 0.996 OwnerLoad: 0.000 11/25 18:19 slot1: State: Owner Activity: Idle 11/25 18:19 slot2: State: Claimed Activity: Busy
Shared system resources are printed without the header, such as total swap space, and slot-specific messages, such as the load average or state of each slot, get the slot number appended.
use feature : GPUs
Use of this configuration templdate invokes the condor_gpu_discovery tool to create a custom resource, with a custom resource name of GPUs, and it generates the ClassAd attributes needed to advertise the GPUs. condor_gpu_discovery is invoked in a mode that discovers and advertises both CUDA and OpenCL GPUs.
This configuration template refers to macro GPU_DISCOVERY_EXTRA, which can be used to define additional command line arguments for the condor_gpu_discovery tool. For example, setting
use feature : GPUs GPU_DISCOVERY_EXTRA = -extracauses the condor_gpu_discovery tool to output more attributes that describe the detected GPUs on the machine.
The STARTD_ATTRS (and legacy STARTD_EXPRS) settings can be configured on a per-slot basis. The condor_startd daemon builds the list of items to advertise by combining the lists in this order:
For example, consider the following configuration:
STARTD_ATTRS = favorite_color, favorite_season SLOT1_STARTD_ATTRS = favorite_movie SLOT2_STARTD_ATTRS = favorite_song
This will result in the condor_startd ClassAd for slot1 defining values for favorite_color, favorite_season, and favorite_movie. Slot2 will have values for favorite_color, favorite_season, and favorite_song.
Attributes themselves in the STARTD_ATTRS list can also be defined on a per-slot basis. Here is another example:
favorite_color = "blue" favorite_season = "spring" STARTD_ATTRS = favorite_color, favorite_season SLOT2_favorite_color = "green" SLOT3_favorite_season = "summer"
For this example, the condor_startd ClassAds are
favorite_color = "blue" favorite_season = "spring"
favorite_color = "green" favorite_season = "spring"
favorite_color = "blue" favorite_season = "summer"
Dynamic provisioning, also referred to as partitionable or dynamic slots, allows HTCondor to use the resources of a slot in a dynamic way; these slots may be partitioned. This means that more than one job can occupy a single slot at any one time. Slots have a fixed set of resources which include the cores, memory and disk space. By partitioning the slot, the use of these resources becomes more flexible.
Here is an example that demonstrates how resources are divided as more than one job is or can be matched to a single slot. In this example, Slot1 is identified as a partitionable slot and has the following resources:
After allocation, the partitionable Slot1 advertises that it has the following resources still available:
To enable dynamic provisioning, define a slot type. and declare at least one slot of that type. Then, identify that slot type as partitionable by setting configuration variable SLOT_TYPE_<N>_PARTITIONABLE to True. The value of <N> within the configuration variable name is the same value as in slot type definition configuration variable SLOT_TYPE_<N>. For the most common cases the machine should be configured for one slot, managing all the resources on the machine. To do so, set the following configuration variables:
NUM_SLOTS = 1 NUM_SLOTS_TYPE_1 = 1 SLOT_TYPE_1 = 100% SLOT_TYPE_1_PARTITIONABLE = TRUE
In a pool using dynamic provisioning, jobs can have extra, and desired, resources specified in the submit description file:
This example shows a portion of the job submit description file for use when submitting a job to a pool with dynamic provisioning.
universe = vanilla request_cpus = 3 request_memory = 1024 request_disk = 10240 queue
Each partitionable slot will have the ClassAd attributes
PartitionableSlot = True SlotType = "Partitionable"Each dynamic slot will have the ClassAd attributes
DynamicSlot = True SlotType = "Dynamic"These attributes may be used in a START expression for the purposes of creating detailed policies.
A partitionable slot will always appear as though it is not running a job. If matched jobs consume all its resources, the partitionable slot will eventually show as having no available resources; this will prevent further matching of new jobs. The dynamic slots will show as running jobs. The dynamic slots can be preempted in the same way as all other slots.
Dynamic provisioning provides powerful configuration possibilities, and so should be used with care. Specifically, while preemption occurs for each individual dynamic slot, it cannot occur directly for the partitionable slot, or for groups of dynamic slots. For example, for a large number of jobs requiring 1GB of memory, a pool might be split up into 1GB dynamic slots. In this instance a job requiring 2GB of memory will be starved and unable to run. A partial solution to this problem is provided by defragmentation accomplished by the condor_defrag daemon, as discussed in section 3.7.1.
Another partial solution is a new matchmaking algorithm in the negotiator, referred to as partitionable slot preemption, or pslot preemption. Without pslot preemption, when the negotiator searches for a match for a job, it looks at each slot ClassAd individually. With pslot preemption, the negotiator looks at a partitionable slot and all of its dynamic slots as a group. If the partitionable slot does not have sufficient resources (memory, cpu, and disk) to be matched with the candidate job, then the negotiator looks at all of the related dynamic slots that the candidate job might preempt (following the normal preemption rules described elsewhere). The resources of each dynamic slot are added to those of the partitionable slot, one dynamic slot at a time. Once this partial sum of resources is sufficient to enable a match, the negotiator sends the match information to the condor_schedd. When the condor_schedd claims the partitionable slot, the dynamic slots are preempted, such that their resources are returned to the partitionable slot for use by the new job.
To enable pslot preemption, the following configuration variable must be set for the condor_negotiator:
ALLOW_PSLOT_PREEMPTION = True
When the negotiator examines the resources of dynamic slots, it sorts the slots by their CurrentRank attribute, such that slots with lower values are considered first. The negotiator only examines the cpu, memory and disk resources of the dynamic slots; custom resources are ignored.
Dynamic slots that have retirement time remaining are not considered eligible for preemption, regardless of how configuration variable NEGOTIATOR_CONSIDER_EARLY_PREEMPTION is set.
When pslot preemption is enabled, the negotiator will not preempt dynamic slots directly. It will preempt them only as part of a match to a partitionable slot.
When multiple partitionable slots match a candidate job and the various job rank expressions are evaluated to sort the matching slots, the ClassAd of the partitionable slot is used for evaluation. This may cause unexpected results for some expressions, as attributes such as RemoteOwner will not be present in a partitionable slot that matches with preemption of some of its dynamic slots.
If a job does not specify the required number of CPUs, amount of memory, or disk space, there are ways for the administrator to set default values for all of these parameters.
First, if any of these attributes are not set in the submit description file, there are three variables in the configuration file that condor_submit will use to fill in default values. These are
The value of these variables can be ClassAd expressions. The default values for these variables, should they not be set are
Note that these default values are chosen such that jobs matched to partitionable slots function similar to static slots.
Once the job has been matched, and has made it to the execute machine, the condor_startd has the ability to modify these resource requests before using them to size the actual dynamic slots carved out of the partitionable slot. Clearly, for the job to work, the condor_startd daemon must create slots with at least as many resources as the job needs. However, it may be valuable to create dynamic slots somewhat bigger than the job's request, as subsequent jobs may be more likely to reuse the newly created slot when the initial job is done using it.
The condor_startd configuration variables which control this and their defaults are
All specification of the resources available is done by configuration of the partitionable slot. The machine is identified as having a resource consumption policy enabled with
CONSUMPTION_POLICY = TrueA defined slot type that is partitionable may override the machine value with
SLOT_TYPE_<N>_CONSUMPTION_POLICY = True
A job seeking a match may always request a specific number of cores, amount of memory, and amount of disk space. Availability of these three resources on a machine and within the partitionable slot is always defined and have these default values:
CONSUMPTION_CPUS = quantize(target.RequestCpus,{1})
CONSUMPTION_MEMORY = quantize(target.RequestMemory,{128})
CONSUMPTION_DISK = quantize(target.RequestDisk,{1024})
Here is an example-driven definition of a consumption policy. Assume a single partitionable slot type on a multi-core machine with 8 cores, and that the resource this policy cares about allocating are the cores. Configuration for the machine includes the definition of the slot type and that it is partitionable.
SLOT_TYPE_1 = cpus=8 SLOT_TYPE_1_PARTITIONABLE = True NUM_SLOTS_TYPE_1 = 1
Enable use of the condor_negotiator-side resource consumption policy, allocating the job-requested number of cores to the dynamic slot, and use SLOT_WEIGHT to assess the user usage that will affect user priority by the number of cores allocated. Note that the only attributes valid within the SLOT_WEIGHT expression are Cpus, Memory, and disk. This must the set to the same value on all machines in the pool.
SLOT_TYPE_1_CONSUMPTION_POLICY = True SLOT_TYPE_1_CONSUMPTION_CPUS = TARGET.RequestCpus SLOT_WEIGHT = Cpus
If custom resources are available within the partitionable slot, they may be used in a consumption policy, by specifying the resource. Using a machine with 4 GPUs as an example custom resource, define the resource and include it in the definition of the partitionable slot:
MACHINE_RESOURCE_NAMES = gpus MACHINE_RESOURCE_gpus = 4 SLOT_TYPE_2 = cpus=8, gpus=4 SLOT_TYPE_2_PARTITIONABLE = True NUM_SLOTS_TYPE_2 = 1
Add the consumption policy to incorporate availability of the GPUs:
SLOT_TYPE_2_CONSUMPTION_POLICY = True SLOT_TYPE_2_CONSUMPTION_gpus = TARGET.RequestGpu SLOT_WEIGHT = Cpus
When partitionable slots are used, some attention must be given to the problem of the starvation of large jobs due to the fragmentation of resources. The problem is that over time the machine resources may become partitioned into slots suitable for running small jobs. If a sufficient number of these slots do not happen to become idle at the same time on a machine, then a large job will not be able to claim that machine, even if the large job has a better priority than the small jobs.
One way of addressing the partitionable slot fragmentation problem is to periodically drain all jobs from fragmented machines so that they become defragmented. The condor_defrag daemon implements a configurable policy for doing that. Its implementation is targeted at machines configured to run whole-machine jobs and at machines that only have partitionable slots. The draining of a machine configured to have both partitionable slots and static slots would have a negative impact on single slot jobs running in static slots.
To use this daemon, DEFRAG must be added to DAEMON_LIST, and the defragmentation policy must be configured. Typically, only one instance of the condor_defrag daemon would be run per pool. It is a lightweight daemon that should not require a lot of system resources.
Here is an example configuration that puts the condor_defrag daemon to work:
DAEMON_LIST = $(DAEMON_LIST) DEFRAG DEFRAG_INTERVAL = 3600 DEFRAG_DRAINING_MACHINES_PER_HOUR = 1.0 DEFRAG_MAX_WHOLE_MACHINES = 20 DEFRAG_MAX_CONCURRENT_DRAINING = 10
This example policy tells condor_defrag to initiate draining jobs from 1 machine per hour, but to avoid initiating new draining if there are 20 completely defragmented machines or 10 machines in a draining state. A full description of each configuration variable used by the condor_defrag daemon may be found in section 3.5.34.
By default, when a machine is drained, existing jobs are gracefully evicted. This means that each job will be allowed to use the remaining time promised to it by MaxJobRetirementTime. If the job has not finished when the retirement time runs out, the job will be killed with a soft kill signal, so that it has an opportunity to save a checkpoint (if the job supports this). No new jobs will be allowed to start while the machine is draining. To reduce unused time on the machine caused by some jobs having longer retirement time than others, the eviction of jobs with shorter retirement time is delayed until the job with the longest retirement time needs to be evicted.
There is a trade off between reduced starvation and throughput. Frequent draining of machines reduces the chance of starvation of large jobs. However, frequent draining reduces total throughput. Some of the machine's resources may go unused during draining, if some jobs finish before others. If jobs that cannot produce checkpoints are killed because they run past the end of their retirement time during draining, this also adds to the cost of draining.
To help gauge the costs of draining, the condor_startd advertises the accumulated time that was unused due to draining and the time spent by jobs that were killed due to draining. These are advertised respectively in the attributes TotalMachineDrainingUnclaimedTime and TotalMachineDrainingBadput. The condor_defrag daemon averages these values across the pool and advertises the result in its daemon ClassAd in the attributes AvgDrainingBadput and AvgDrainingUnclaimed. Details of all attributes published by the condor_defrag daemon are described in section 13.
The following command may be used to view the condor_defrag daemon ClassAd:
condor_status -l -any -constraint 'MyType == "Defrag"'
There are two types of schedd policy: job transforms (which change the ClassAd of a job at submission) and submit requirements (which prevent some jobs from entering the queue). These policies are explained below.
The condor_schedd can transform jobs as they are submitted. Transformations can be used to guarantee the presence of required job attributes, to set defaults for job attributes the user does not supply, or to modify job attributes so that they conform to schedd policy; an example of this might be to automatically set accounting attributes based on the owner of the job while letting the job owner indicate a preference.
There can be multiple job transforms. Each transform can have a Requirements expression to indicate which jobs it should transform and which it should ignore. Transforms without a Requirements expression apply to all jobs. Job transforms are applied in order. The set of transforms and their order are configured using the Configuration variable JOB_TRANSFORM_NAMES.
For each entry in this list there must be a corresponding JOB_TRANSFORM_<name> configuration variable that specifies the transform rules. Transforms use the same syntax as condor_job_router transforms; although unlike the condor_job_router there is no default transform, and all matching transforms are applied - not just the first one. (See 5.4 for information on the condor_job_router.)
The following example shows a set of two transforms: one that automatically assigns an accounting group to jobs based on the submitting user, and one that shows one possible way to transform Vanilla jobs to Docker jobs.
JOB_TRANSFORM_NAMES = AssignGroup, SL6ToDocker
JOB_TRANSFORM_AssignGroup = [ eval_set_AccountingGroup = userMap("Groups",Owner,AccountingGroup); ]
JOB_TRANSFORM_SL6ToDocker @=end
[
Requirements = JobUniverse==5 && WantSL6 && DockerImage =?= undefined;
set_WantDocker = true;
set_DockerImage = "SL6";
copy_Requirements = "VanillaRequrements";
set_Requirements = TARGET.HasDocker && VanillaRequirements
]
@end
The AssignGroup transform above assumes that a mapfile that can
map an owner to one or more accounting groups has been configured
via SCHEDD_CLASSAD_USER_MAP_NAMES, and given the name
"Groups".
The SL6ToDocker transform above is most likely incomplete, as it
assumes some custom attributes (WantSL6 and WantDocker and
HasDocker) that your pool may or may not use.
The condor_schedd may reject job submissions, such that rejected jobs never enter the queue. Rejection may be best for the case in which there are jobs that will never be able to run; an example of this might be all jobs that specify the standard universe in a queue with restricted networking. Another appropriate example might be to reject all jobs that do not request a minimum amount of memory. Or, it may be appropriate to prevent certain users from using a specific submit host.
Rejection criteria are configured. Configuration variable SUBMIT_REQUIREMENT_NAMES lists criteria, where each criterion is given a name. The chosen name is a major component of the default error message output if a user attempts to submit a job which fails to meet the requirements. Therefore, choose a descriptive name. For the three example submit requirements described:
SUBMIT_REQUIREMENT_NAMES = NotStandardUniverse, MinimalRequestMemory, NotChris
The criterion for each submit requirement is then specified in configuration variable SUBMIT_REQUIREMENT_<Name>, where <Name> matches the chosen name listed in SUBMIT_REQUIREMENT_NAMES. The value is a boolean ClassAd expression. The three example criterion result in these configuration variable definitions:
SUBMIT_REQUIREMENT_NotStandardUniverse = JobUniverse != 1 SUBMIT_REQUIREMENT_MinimalRequestMemory = RequestMemory > 512 SUBMIT_REQUIREMENT_NotChris = Owner != "chris"
Submit requirements are evaluated in the listed order; the first requirement that evaluates to False causes rejection of the job, terminates further evaluation of other submit requirements, and is the only requirement reported. Each submit requirement is evaluated in the context of the condor_schedd ClassAd, which is the MY. name space and the job ClassAd, which is the TARGET. name space. Note that JobUniverse and RequestMemory are both job ClassAd attributes.
Further configuration may associate a rejection reason with a submit requirement with the SUBMIT_REQUIREMENT_<Name>_REASON.
SUBMIT_REQUIREMENT_NotStandardUniverse_REASON = "This pool does not accept standard universe jobs." SUBMIT_REQUIREMENT_MinimalRequestMemory_REASON = strcat( "The job only requested ", \ RequestMemory, " Megabytes. If that small amount is really enough, please contact ..." ) SUBMIT_REQUIREMENT_NotChris_REASON = "Chris, you may only submit jobs to the instructional pool."
The value must be a ClassAd expression which evaluates to a string. Thus, double quotes were required to make strings for both SUBMIT_REQUIREMENT_NotStandardUniverse_REASON and SUBMIT_REQUIREMENT_NotChris_REASON. The ClassAd function strcat() produces a string in the definition of SUBMIT_REQUIREMENT_MinimalRequestMemory_REASON.
Rejection reasons are sent back to the submitting program and will typically be immediately presented to the user. If an optional SUBMIT_REQUIREMENT_<Name>_REASON is not defined, a default reason will include the <Name> chosen for the submit requirement. Completing the presentation of the example submit requirements, upon an attempt to submit a standard universe job, condor_submit would print
Submitting job(s). ERROR: Failed to commit job submission into the queue. ERROR: This pool does not accept standard universe jobs.
Where there are multiple jobs in a cluster, if any job within the cluster is rejected due to a submit requirement, the entire cluster of jobs will be rejected.
Starting in HTCondor 8.7.4, you may instead configure submit warnings. A submit warning is a submit requirement for which SUBMIT_REQUIREMENT_<Name>_IS_WARNING is true. A submit warning does not cause the submission to fail; instead, it returns a warning to the user's console (when triggered via condor_submit) or writes a message to the user log (always). Submit warnings are intended to allow HTCondor administrators to provide their users with advance warning of new submit requirements. For example, if you want to increase the minimum request memory, you could use the following configuration.
SUBMIT_REQUIREMENT_NAMES = OneGig $(SUBMIT_REQUIREMENT_NAMES) SUBMIT_REQUIREMENT_OneGig = RequestMemory > 1024 SUBMIT_REQUIREMENT_OneGig_REASON = "As of <date>, the minimum requested memory will be 1024." SUBMIT_REQUIREMENT_OneGig_IS_WARNING = TRUE
When a user runs condor_submit to submit a job with RequestMemory between 512 and 1024, they will see (something like) the following, assuming that the job meets all the other requirements.
Submitting job(s). WARNING: Committed job submission into the queue with the following warning: WARNING: As of <date>, the minimum requested memory will be 1024. 1 job(s) submitted to cluster 452.
The job will contain (something like) the following:
000 (452.000.000) 10/06 13:40:45 Job submitted from host: <128.105.136.53:37317?addrs=128.105.136.53-37317+[fc00--1]-37317&noUDP&sock=19966_e869_5>
WARNING: Committed job submission into the queue with the following warning: As of <date>, the minimum requested memory will be 1024.
...
Marking a submit requirement as a warning does not change when or how it is evaluated, only the result of doing so. In particular, failing a submit warning does not terminate further evaluation of the submit requirements list. Currently, only one (the most recent) problem is reported for each submit attempt. This means users will see (as they previously did) only the first failed requirement; if all requirements passed, they will see the last failed warning, if any.