



Next: condor_qedit
Up: 11. Command Reference Manual
Previous: condor_procd
Contents
Index
Subsections
condor_q
Display information about jobs in queue
condor_q
[-help [Universe | State]]
condor_q
[-debug]
[general options]
[restriction list]
[output options]
[analyze options]
condor_q displays information about jobs in the HTCondor job queue. By
default, condor_q queries the local job queue,
but this behavior may be
modified by specifying one of the general options.
As of version 8.5.2, condor_q defaults to querying only the current
user's jobs. This default is overridden when the restriction list has
usernames and/or job ids, when the -submitter or -allusers
arguments are specified, or when the current user is a queue superuser.
It can also be overridden by setting the
CONDOR_Q_ONLY_MY_JOBS configuration macro to False.
As of version 8.5.6, condor_q defaults to batch-mode
output (see -batch in the Options section below).
The old behavior can be obtained by specifying -nobatch
on the command line.
To change the default back to its pre-8.5.6 value, set the new
configuration variable CONDOR_Q_DASH_BATCH_IS_DEFAULT to
False.
As of version 8.5.6, condor_q defaults to displaying information about
batches of jobs, rather than individual jobs. The intention is that
this will be a more useful, and user-friendly, format for users with
large numbers of jobs in the queue. Ideally, users will specify
meaningful batch names for their jobs, to make it easier to keep
track of related jobs.
(For information about specifying batch names for your jobs, see the
condor_submit ( 11) and condor_submit_dag
( 11) man pages.)
A batch of jobs is defined as follows:
- An entire workflow (a DAG or hierarchy of nested DAGs)
(note that condor_dagman now specifies a default batch
name for all jobs in a given workflow)
- All jobs in a single cluster
- All jobs submitted by a single user that have the same
executable specified in their submit file (unless submitted
with different batch names)
- All jobs submitted by a single user that have the same
batch name specified in their submit file or on the condor_submit
or condor_submit_dag command line.
There are many output options that modify the output generated by
condor_q. The effects of these options, and the meanings of the
various output data, are described below.
If the -long option is specified, condor_q displays a long description
of the queried jobs by printing the entire job ClassAd for all jobs
matching the restrictions, if any.
Individual attributes of the job ClassAd can be displayed by means of the
-format option, which displays attributes with a printf(3)
format, or with the -autoformat option.
Multiple -format options may be specified in the option list to display
several attributes of the job.
For most output options (except as specified), the last line of
condor_q output contains a summary of the queue: the total
number of jobs, and the number of jobs in the completed, removed,
idle, running, held and suspended states.
If no output options are specified, condor_q now defaults to
batch mode, and displays the following columns of information, with
one line of output per batch of jobs:
OWNER, BATCH_NAME, SUBMITTED, DONE, RUN, IDLE, [HOLD,] TOTAL, JOB_IDS
Note that the HOLD column is only shown if there are held jobs in
the output or if there are no jobs in the output.
If the -nobatch option is specified, condor_q displays the
following columns of information, with one line of output
per job:
ID, OWNER, SUBMITTED, RUN_TIME, ST, PRI, SIZE, CMD
If the -dag option is specified (in conjunction with -nobatch),
condor_q displays the following columns of information, with one line
of output per job; the owner is shown only for top-level jobs, and for
all other jobs (including sub-DAGs) the node name is shown:
ID, OWNER/NODENAME, SUBMITTED, RUN_TIME, ST, PRI, SIZE, CMD
If the -run option is specified (in conjunction with -nobatch),
condor_q displays the following columns of information, with one line
of output per running job:
ID, OWNER, SUBMITTED, RUN_TIME, HOST(S)
Also note that the -run option disables output of the
totals line.
If the -grid option is specified, condor_q displays the
following columns of information, with one line of output per job:
ID, OWNER, STATUS, GRID->MANAGER, HOST, GRID_JOB_ID
If the -goodput option is specified, condor_q displays the
following columns of information, with one line of output per job:
ID, OWNER, SUBMITTED, RUN_TIME, GOODPUT, CPU_UTIL, Mb/s
If the -io option is specified, condor_q displays the
following columns of information, with one line of output per job:
ID, OWNER, RUNS, ST, INPUT, OUTPUT, RATE, MISC
If the -cputime option is specified (in conjunction with -nobatch),
condor_q displays the
following columns of information, with one line of output per job:
ID, OWNER, SUBMITTED, CPU_TIME, ST, PRI, SIZE, CMD
If the -hold option is specified, condor_q displays the
following columns of information, with one line of output per job:
ID, OWNER, HELD_SINCE, HOLD_REASON
If the -totals option is specified, condor_q displays
only one line of output no matter how many jobs and batches of
jobs are in the queue. That line of output contains the total
number of jobs, and the number of jobs in the completed, removed,
idle, running, held and suspended states.
The available output data are as follows:
- ID
- (Non-batch mode only) The cluster/process id of the HTCondor job.
- OWNER
- The owner of the job or batch of jobs.
- OWNER/NODENAME
- (-dag only) The owner of a job or the
DAG node name of the job.
- BATCH_NAME
- (Batch mode only) The batch name of the job or batch
of jobs.
- SUBMITTED
- The month, day, hour, and minute the job was submitted
to the queue.
- DONE
- (Batch mode only) The number of job procs that are done, but
still in the queue.
- RUN
- (Batch mode only) The number of job procs that are running.
- IDLE
- (Batch mode only) The number of job procs that are in the
queue but idle.
- HOLD
- (Batch mode only) The number of job procs that are in the
queue but held.
- TOTAL
- (Batch mode only) The total number of job procs in the
queue, unless the batch is a DAG, in which case this is the total
number of clusters in the queue. Note: for non-DAG batches,
the TOTAL column contains correct values only in version 8.5.7
and later.
- JOB_IDS
- (Batch mode only) The range of job IDs belonging to the batch.
- RUN_TIME
- (Non-batch mode only) Wall-clock time accumulated by
the job to date in days, hours, minutes, and seconds.
- ST
- (Non-batch mode only) Current status of the job, which varies
somewhat according
to the job universe and the timing of updates.
H = on hold,
R = running,
I = idle
(waiting for a machine to execute on), C = completed,
X = removed,
S = suspended (execution of a running job temporarily suspended on execute node),
< = transferring input (or queued to do so), and
> = transferring output (or queued to do so).
- PRI
- (Non-batch mode only) User specified priority of the job,
displayed as an integer, with higher numbers corresponding to better
priority.
- SIZE
- (Non-batch mode only) The peak amount of memory in Mbytes
consumed by the job; note this value is only refreshed periodically.
The actual value reported is taken from the job ClassAd attribute
MemoryUsage if this attribute is defined, and from job
attribute ImageSize otherwise.
- CMD
- (Non-batch mode only) The name of the executable.
- HOST(S)
- (-run only) The host where the job is running.
- STATUS
- (-grid only) The state that HTCondor believes the job is in.
Possible values are
- PENDING
- The job is waiting for resources to become available
in order to run.
- ACTIVE
- The job has received resources, and the application
is executing.
- FAILED
- The job terminated before completion because of an error,
user-triggered cancel, or system-triggered cancel.
- DONE
- The job completed successfully.
- SUSPENDED
- The job has been suspended.
Resources which were allocated for this job may have been
released due to a scheduler-specific reason.
- UNSUBMITTED
- The job has not been submitted to the scheduler yet,
pending the reception of the
GLOBUS_GRAM_PROTOCOL_JOB_SIGNAL_COMMIT_REQUEST signal from a client.
- STAGE_IN
- The job manager is staging in files,
in order to run the job.
- STAGE_OUT
- The job manager is staging out files
generated by the job.
- UNKNOWN
-
- GRID->MANAGER
- (-grid only) A guess at what remote batch system is running the job.
It is a guess, because HTCondor looks at the Globus jobmanager contact
string to attempt identification.
If the value is fork, the job is running on the
remote host without a jobmanager.
Values may also be condor, lsf, or pbs.
- HOST
- (-grid only) The host to which the job was submitted.
- GRID_JOB_ID
- (-grid only) (More information needed here.)
- GOODPUT
- (-goodput only) The percentage of RUN_TIME for this job which has been
saved in a checkpoint. A low GOODPUT value indicates that the job is
failing to checkpoint. If a job has not yet attempted a checkpoint,
this column contains [?????].
- CPU_UTIL
- (-goodput only) The ratio of CPU_TIME to RUN_TIME for checkpointed
work. A low CPU_UTIL indicates that the job is not running
efficiently, perhaps because it is I/O bound or because the job
requires more memory than available on the remote workstations. If
the job has not (yet) checkpointed, this column contains [??????].
- Mb/s
- (-goodput only) The network usage of this job, in
Megabits per second of run-time.
- READ The total number of bytes the application has read from
files and sockets.
- WRITE The total number of bytes the application has written to
files and sockets.
- SEEK The total number of seek operations the application has
performed on files.
- XPUT The effective throughput (average bytes read and written
per second)
from the application's point of view.
- BUFSIZE The maximum number of bytes to be buffered per file.
- BLOCKSIZE The desired block size for large data transfers.
These fields are updated when a job produces a checkpoint or completes.
If a job has not yet produced a checkpoint, this information is not
available.
- INPUT
- (-io only) For standard universe, FileReadBytes;
otherwise, BytesRecvd.
- OUTPUT
- (-io only) For standard universe, FileWriteBytes;
otherwise, BytesSent.
- RATE
- (-io only) For standard universe,
FileReadBytes+FileWriteBytes; otherwise, BytesRecvd+BytesSent.
- MISC
- (-io only) JobUniverse.
- CPU_TIME
- (-cputime only) The remote CPU time accumulated by
the job to date
(which has been stored in a checkpoint) in days, hours, minutes, and
seconds. (If the job is currently running, time accumulated during
the current run is not shown. If the job has not produced a
checkpoint, this column contains 0+00:00:00.)
- HELD_SINCE
- (-hold only) Month, day, hour and minute
at which the job was held.
- HOLD_REASON
- (-hold only) The hold reason for the job.
The -analyze or -better-analyze options can be used to determine
why certain jobs are not
running by performing an analysis on a per machine basis for each machine in
the pool. The reasons can vary among failed constraints, insufficient priority,
resource owner preferences and prevention of preemption by the
PREEMPTION_REQUIREMENTS expression.
If the analyze option -verbose is specified
along with the -analyze option, the reason for failure is displayed on a
per machine basis.
-better-analyze differs from -analyze in that it will
do matchmaking analysis on jobs even if they are currently running,
or if the reason they are not running is not due to matchmaking.
-better-analyze also produces
more thorough analysis of complex Requirements and shows the values of
relevant job ClassAd attributes.
When only a single machine is being analyzed via -machine or
-mconstraint,
the values of relevant attributes of the machine ClassAd are also displayed.
To restrict the display to jobs of interest, a list of zero or more
restriction options may be supplied. Each restriction may be one of:
- cluster.process, which matches jobs which
belong to the specified cluster and have the specified process number;
- cluster (without a process), which matches all jobs belonging
to the specified cluster;
- owner, which matches all jobs owned by the specified owner;
- -constraint expression, which matches all jobs that
satisfy the specified ClassAd expression;
- -allusers, which overrides the default
restriction of only matching jobs submitted by the
current user.
If cluster or cluster.process is specified, and
the job matching that restriction is a condor_dagman job, information
for all jobs of that DAG is displayed in batch mode (in non-batch
mode, only the condor_dagman job itself is displayed).
If no owner restrictions are present, the job matches the
restriction list if it matches at least one restriction in the list. If
owner restrictions are present, the job matches the list if it matches
one of the owner restrictions and at least one non-owner
restriction.
- -debug
- Causes debugging information to be sent to
stderr, based on the value of the configuration variable
TOOL_DEBUG.
- -batch
- (output option) Show a single line of progress
information for a batch of jobs, where a batch is defined as follows:
- An entire workflow (a DAG or hierarchy of nested DAGs)
- All jobs in a single cluster
- All jobs submitted by a single user that have the same
executable specified in their submit file
- All jobs submitted by a single user that have the same
batch name specified in their submit file or on the condor_submit
or condor_submit_dag command line.
Also change the output columns as noted above.
Note that, as of version 8.5.6, -batch is the default,
unless the CONDOR_Q_DASH_BATCH_IS_DEFAULT
configuration variable is set to False.
- -nobatch
- (output option) Show a line for each job (turn
off the -batch option).
- -global
- (general option) Queries all job queues in the pool.
- -submitter submitter
- (general option) List jobs of
a specific submitter in the entire pool, not just for a single condor_schedd.
- -name name
- (general option) Query only the job queue
of the named condor_schedd daemon.
- -pool centralmanagerhostname[:portnumber]
- (general option) Use the centralmanagerhostname as
the central manager to locate condor_schedd daemons.
The default is the COLLECTOR_HOST,
as specified in the configuration.
- -jobads file
- (general option) Display jobs from a list of
ClassAds from a file, instead of the real ClassAds from the
condor_schedd daemon.
This is most useful for debugging purposes.
The ClassAds appear as if
condor_q -long is used with the header stripped out.
- -userlog file
- (general option)
Display jobs, with job information coming from a job event log,
instead of from the real ClassAds from the condor_schedd daemon.
This is most useful for automated testing of the status of jobs known to be
in the given job event log, because it reduces the load on the condor_schedd.
A job event log does not contain all of the job information, so some fields in
the normal output of condor_q will be blank.
- -autocluster
- (output option)
Output condor_schedd daemon auto cluster information.
For each auto cluster,
output the unique ID of the auto cluster
along with the number of jobs in that auto cluster.
This option is intended to be used together with the -long option
to output the ClassAds representing auto clusters.
The ClassAds can then be used to identify or classify the demand for
sets of machine resources,
which will be useful in the on-demand creation of execute nodes for
glidein services.
- -cputime
- (output option)
Instead of wall-clock allocation time (RUN_TIME),
display remote CPU time accumulated by the job to date in days,
hours, minutes, and seconds. If the job is currently running, time
accumulated during the current run is not shown.
Note that this option has no effect unless used
in conjunction with -nobatch.
- -currentrun
- (output option)
Normally, RUN_TIME contains all the time
accumulated during the current run plus all previous runs. If this
option is specified, RUN_TIME only displays the time accumulated so
far on this current run.
- -dag
- (output option) Display DAG node jobs
under their DAGMan instance.
Child nodes are listed using indentation to show the structure
of the DAG. Note that this option has no effect unless used
in conjunction with -nobatch.
- -expert
- (output option) Display shorter error messages.
- -grid
- (output option) Get information only about
jobs submitted to grid resources described as gt2
or gt5.
- -goodput
- (output option) Display job goodput statistics.
- -help [Universe | State]
- (output option) Print usage info,
and, optionally, additionally print job universes or job states.
- -hold
- (output option) Get information about jobs in
the hold state.
Also displays the time the job was placed into the hold state
and the reason why the job was placed in the hold state.
- -limit Number
- (output option)
Limit the number of items output to Number.
- -io
- (output option) Display job input/output summaries.
- -long
- (output option) Display entire job ClassAds
in long format (one attribute per line).
- -run
- (output option) Get information about running jobs.
Note that this option has no effect unless used
in conjunction with -nobatch.
- -stream-results
- (output option)
Display results as jobs are fetched
from the job queue rather than storing results in memory until all
jobs have been fetched. This can reduce memory consumption when fetching
large numbers of jobs, but if condor_q is paused while displaying
results, this could result in a timeout in communication with
condor_schedd.
- -totals
- (output option) Display only the totals.
- -version
- (output option) Print the HTCondor version and exit.
- -wide
- (output option) If this option is specified,
and the command portion
of the output would cause the output to extend beyond 80 columns,
display beyond the 80 columns.
- -xml
- (output option) Display entire job ClassAds
in XML format.
The XML format is fully defined in the reference manual,
obtained from the ClassAds web page, with a link at
http://research.cs.wisc.edu/htcondor/research.html.
- -json
- (output option) Display entire job ClassAds
in JSON format.
- -attributes Attr1[,Attr2 ... ]
- (output option)
Explicitly list the attributes,
by name in a comma separated list,
which should be displayed when using the -xml, -json or -long options.
Limiting the number of attributes increases the efficiency of the query.
- -format fmt attr
- (output option) Display attribute or
expression attr in format fmt.
To display the attribute or expression the format must contain a single
printf(3)-style conversion specifier.
Attributes must be from the job ClassAd.
Expressions are ClassAd expressions and may
refer to attributes in the job ClassAd.
If the attribute is not present in a given ClassAd and cannot
be parsed as an expression,
then the format option will be silently skipped.
%r prints the unevaluated, or raw values.
The conversion specifier must match the type of the
attribute or expression.
%s is suitable for strings such as Owner,
%d for integers such as ClusterId,
and %f for floating point numbers such as RemoteWallClockTime.
%v identifies the type of the attribute,
and then prints the value in an appropriate format.
%V identifies the type of the attribute,
and then prints the value in an appropriate format as it would
appear in the -long format.
As an example, strings used with %V will have quote marks.
An incorrect format will result in undefined behavior.
Do not use more than one conversion specifier in a given
format. More than one conversion specifier will result
in undefined behavior. To output multiple attributes
repeat the -format option once for each desired attribute.
Like printf(3) style formats, one may include other
text that will be reproduced directly.
A format without any conversion specifiers may be specified,
but an attribute is still required.
Include
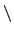 n to specify a line break.
n to specify a line break.
- -autoformat[:jlhVr,tng] attr1 [attr2 ...]
or -af[:jlhVr,tng] attr1 [attr2 ...]
- (output option) Display attribute(s) or expression(s)
formatted in a default way according to attribute types.
This option takes an arbitrary number of attribute names as arguments,
and prints out their values,
with a space between each value and a newline character after
the last value.
It is like the -format option without format strings.
This output option does not work in conjunction with any of the
options -run, -currentrun, -hold,
-grid, -goodput, or -io.
It is assumed that no attribute names begin with a dash character,
so that the next word that begins with dash is the
start of the next option.
The autoformat option may be followed by a colon character
and formatting qualifiers to deviate the output formatting from
the default:
j print the job ID as the first field,
l label each field,
h print column headings before the first line of output,
V use %V rather than %v for formatting (string values
are quoted),
r print "raw", or unevaluated values,
, add a comma character after each field,
t add a tab character before each field instead of
the default space character,
n add a newline character after each field,
g add a newline character between ClassAds, and
suppress spaces before each field.
Use -af:h to get tabular values with headings.
Use -af:lrng to get -long equivalent format.
The newline and comma characters may not be used together.
The l and h characters may not be used
together.
- -analyze[:<qual>]
- (analyze option) Perform a matchmaking
analysis on why the requested jobs are not running.
First a simple analysis determines if the job is not running
due to not being in a runnable state.
If the job is in a runnable state, then this option is equivalent
to -better-analyze.
<qual> is a comma separated list containing one or more of
priority to consider user priority during the analysis
summary to show a one line summary for each job or machine
reverse to analyze machines, rather than jobs
- -better-analyze[:<qual>]
- (analyze option)
Perform a more detailed matchmaking analysis to determine how
many resources are available to run the requested jobs.
This option
is never meaningful for Scheduler universe jobs and only meaningful
for grid universe jobs doing matchmaking.
<qual> is a comma separated list containing one or more of
priority to consider user priority during the analysis
summary to show a one line summary for each job or machine
reverse to analyze machines, rather than jobs
- -machine name
- (analyze option)
When doing matchmaking analysis,
analyze only machine ClassAds that have slot or machine names
that match the given name.
- -mconstraint expression
- (analyze option)
When doing matchmaking analysis,
match only machine ClassAds which match the ClassAd expression constraint.
- -slotads file
- (analyze option)
When doing matchmaking analysis, use the
machine ClassAds from the file instead of the ones from the
condor_collector daemon.
This is most useful for debugging purposes.
The ClassAds appear as if condor_status -long is used.
- -userprios file
- (analyze option)
When doing matchmaking analysis with
priority, read user priorities from the file rather than the ones from
the condor_negotiator daemon.
This is most useful for debugging purposes or to
speed up analysis in situations where the condor_negotiator daemon is
slow to respond to condor_userprio requests. The file should be in
the format produced by condor_userprio -long.
- -nouserprios
- (analyze option)
Do not consider user priority during the analysis.
- -reverse
- (analyze option)
Analyze machine requirements against jobs.
- -verbose
- (analyze option)
When doing analysis, show progress and include
the names of specific machines in the output.
The default output from condor_q is formatted to be human readable,
not script readable.
In an effort to make the output fit within 80 characters, values in
some fields might be truncated.
Furthermore, the HTCondor Project can (and does) change the formatting
of this default output as we see fit.
Therefore, any script that is attempting to parse data from condor_q
is strongly encouraged to use the -format option (described
above, examples given below).
Although -analyze provides a very good first approximation, the analyzer
cannot diagnose all possible situations,
because the analysis is based on
instantaneous and local information. Therefore, there are some situations
such as when several submitters are contending for resources, or if the pool
is rapidly changing state which cannot be accurately diagnosed.
Options
-goodput, -cputime, and -io are most useful for standard
universe jobs, since they rely on values computed when a job
produces a checkpoint.
It is possible to to hold jobs that are in the X state.
To avoid this it
is best to construct a -constraint expression that option contains
JobStatus != 3 if the user wishes to avoid this condition.
The -format option provides a way to specify both the job attributes
and formatting of those attributes.
There must be only one conversion specification per -format option.
As an example, to list only Jane Doe's jobs in the queue,
choosing to print and format only the owner of the job,
the command line arguments for the job, and the
process ID of the job:
$ condor_q -submitter jdoe -format "%s" Owner -format " %s " Args -format " ProcId = %d\n" ProcId
jdoe 16386 2800 ProcId = 0
jdoe 16386 3000 ProcId = 1
jdoe 16386 3200 ProcId = 2
jdoe 16386 3400 ProcId = 3
jdoe 16386 3600 ProcId = 4
jdoe 16386 4200 ProcId = 7
To display only the JobID's of Jane Doe's jobs you can use the following.
$ condor_q -submitter jdoe -format "%d." ClusterId -format "%d\n" ProcId
27.0
27.1
27.2
27.3
27.4
27.7
An example that shows the analysis in summary format:
$ condor_q -analyze:summary
-- Submitter: submit-1.chtc.wisc.edu : <192.168.100.43:9618?sock=11794_95bb_3> :
submit-1.chtc.wisc.edu
Analyzing matches for 5979 slots
Autocluster Matches Machine Running Serving
JobId Members/Idle Reqmnts Rejects Job Users Job Other User Avail Owner
---------- ------------ -------- ------------ ---------- ---------- ----- -----
25764522.0 7/0 5910 820 7/10 5046 34 smith
25764682.0 9/0 2172 603 9/9 1531 29 smith
25765082.0 18/0 2172 603 18/9 1531 29 smith
25765900.0 1/0 2172 603 1/9 1531 29 smith
An example that shows summary information by machine:
$ condor_q -ana:sum,rev
-- Submitter: s-1.chtc.wisc.edu : <192.168.100.43:9618?sock=11794_95bb_3> : s-1.chtc.wisc.edu
Analyzing matches for 2885 jobs
Slot Slot's Req Job's Req Both
Name Type Matches Job Matches Slot Match %
------------------------ ---- ------------ ------------ ----------
slot1@INFO.wisc.edu Stat 2729 0 0.00
slot2@INFO.wisc.edu Stat 2729 0 0.00
slot1@aci-001.chtc.wisc.edu Part 0 2793 0.00
slot1_1@a-001.chtc.wisc.edu Dyn 2644 2792 91.37
slot1_2@a-001.chtc.wisc.edu Dyn 2623 2601 85.10
slot1_3@a-001.chtc.wisc.edu Dyn 2644 2632 85.82
slot1_4@a-001.chtc.wisc.edu Dyn 2644 2792 91.37
slot1@a-002.chtc.wisc.edu Part 0 2633 0.00
slot1_10@a-002.chtc.wisc.edu Den 2623 2601 85.10
An example with two independent DAGs in the queue:
$ condor_q
-- Schedd: wenger@manta.cs.wisc.edu : <128.105.14.228:35169?...
OWNER BATCH_NAME SUBMITTED DONE RUN IDLE TOTAL JOB_IDS
wenger DAG: 3696 2/12 11:55 _ 10 _ 10 3698.0 ... 3707.0
wenger DAG: 3697 2/12 11:55 1 1 1 10 3709.0 ... 3710.0
14 jobs; 0 completed, 0 removed, 1 idle, 13 running, 0 held, 0 suspended
Note that the "13 running" in the last line is two more than the
total of the RUN column, because the two condor_dagman jobs
themselves are counted in the last line but not the RUN column.
Also note that the "completed" value in the last line does not
correspond to the total of the DONE column, because the "completed"
value in the last line only counts jobs that are completed but still
in the queue, whereas the DONE column counts jobs that are no
longer in the queue.
Here's an example with a held job, illustrating the addition of
the HOLD column to the output:
$ condor_q
-- Schedd: wenger@manta.cs.wisc.edu : <128.105.14.228:9619?...
OWNER BATCH_NAME SUBMITTED DONE RUN IDLE HOLD TOTAL JOB_IDS
wenger CMD: /bin/slee 9/13 16:25 _ 3 _ 1 4 599.0 ...
4 jobs; 0 completed, 0 removed, 0 idle, 3 running, 1 held, 0 suspended
Here are some examples with a nested-DAG workflow in the queue, which
is one of the most complicated cases. The workflow consists of a
top-level DAG with nodes NodeA and NodeB, each with two two-proc clusters;
and a sub-DAG SubZ with nodes NodeSA and NodeSB, each with two two-proc
clusters.
First of all, non-batch mode with all of the node jobs in the queue:
$ condor_q -nobatch
-- Schedd: wenger@manta.cs.wisc.edu : <128.105.14.228:9619?...
ID OWNER SUBMITTED RUN_TIME ST PRI SIZE CMD
591.0 wenger 9/13 16:05 0+00:00:13 R 0 2.4 condor_dagman -p 0
592.0 wenger 9/13 16:05 0+00:00:07 R 0 0.0 sleep 60
592.1 wenger 9/13 16:05 0+00:00:07 R 0 0.0 sleep 300
593.0 wenger 9/13 16:05 0+00:00:07 R 0 0.0 sleep 60
593.1 wenger 9/13 16:05 0+00:00:07 R 0 0.0 sleep 300
594.0 wenger 9/13 16:05 0+00:00:07 R 0 2.4 condor_dagman -p 0
595.0 wenger 9/13 16:05 0+00:00:01 R 0 0.0 sleep 60
595.1 wenger 9/13 16:05 0+00:00:01 R 0 0.0 sleep 300
596.0 wenger 9/13 16:05 0+00:00:01 R 0 0.0 sleep 60
596.1 wenger 9/13 16:05 0+00:00:01 R 0 0.0 sleep 300
10 jobs; 0 completed, 0 removed, 0 idle, 10 running, 0 held, 0 suspended
Now non-batch mode with the -dag option (unfortunately, condor_q
doesn't do a good job of grouping procs in the same cluster together):
$ condor_q -nobatch -dag
-- Schedd: wenger@manta.cs.wisc.edu : <128.105.14.228:9619?...
ID OWNER/NODENAME SUBMITTED RUN_TIME ST PRI SIZE CMD
591.0 wenger 9/13 16:05 0+00:00:27 R 0 2.4 condor_dagman -
592.0 |-NodeA 9/13 16:05 0+00:00:21 R 0 0.0 sleep 60
593.0 |-NodeB 9/13 16:05 0+00:00:21 R 0 0.0 sleep 60
594.0 |-SubZ 9/13 16:05 0+00:00:21 R 0 2.4 condor_dagman -
595.0 |-NodeSA 9/13 16:05 0+00:00:15 R 0 0.0 sleep 60
596.0 |-NodeSB 9/13 16:05 0+00:00:15 R 0 0.0 sleep 60
592.1 |-NodeA 9/13 16:05 0+00:00:21 R 0 0.0 sleep 300
593.1 |-NodeB 9/13 16:05 0+00:00:21 R 0 0.0 sleep 300
595.1 |-NodeSA 9/13 16:05 0+00:00:15 R 0 0.0 sleep 300
596.1 |-NodeSB 9/13 16:05 0+00:00:15 R 0 0.0 sleep 300
10 jobs; 0 completed, 0 removed, 0 idle, 10 running, 0 held, 0 suspended
Now, finally, the non-batch (default) mode:
$ condor_q
-- Schedd: wenger@manta.cs.wisc.edu : <128.105.14.228:9619?...
OWNER BATCH_NAME SUBMITTED DONE RUN IDLE TOTAL JOB_IDS
wenger ex1.dag+591 9/13 16:05 _ 8 _ 5 592.0 ... 596.1
10 jobs; 0 completed, 0 removed, 0 idle, 10 running, 0 held, 0 suspended
There are several things about this output that may be slightly
confusing:
- The TOTAL column is less than the RUN column. This is because,
for DAG node jobs, their contribution to the TOTAL column is the
number of clusters, not the number of procs (but their contribution
to the RUN column is the number of procs). So the four DAG nodes
(8 procs) contribute 4, and the sub-DAG contributes 1, to the TOTAL column.
(But, somewhat confusingly, the sub-DAG job is not counted
in the RUN column.)
- The sum of the RUN and IDLE columns (8) is less than the 10
jobs listed in the totals line at the bottom. This is because the
top-level DAG and sub-DAG jobs are not counted in the RUN column,
but they are counted in the totals line.
Now here is non-batch mode after proc 0 of each node job has finished:
$ condor_q -nobatch
-- Schedd: wenger@manta.cs.wisc.edu : <128.105.14.228:9619?...
ID OWNER SUBMITTED RUN_TIME ST PRI SIZE CMD
591.0 wenger 9/13 16:05 0+00:01:19 R 0 2.4 condor_dagman -p 0
592.1 wenger 9/13 16:05 0+00:01:13 R 0 0.0 sleep 300
593.1 wenger 9/13 16:05 0+00:01:13 R 0 0.0 sleep 300
594.0 wenger 9/13 16:05 0+00:01:13 R 0 2.4 condor_dagman -p 0
595.1 wenger 9/13 16:05 0+00:01:07 R 0 0.0 sleep 300
596.1 wenger 9/13 16:05 0+00:01:07 R 0 0.0 sleep 300
6 jobs; 0 completed, 0 removed, 0 idle, 6 running, 0 held, 0 suspended
The same state also with the -dag option:
$ condor_q -nobatch -dag
-- Schedd: wenger@manta.cs.wisc.edu : <128.105.14.228:9619?...
ID OWNER/NODENAME SUBMITTED RUN_TIME ST PRI SIZE CMD
591.0 wenger 9/13 16:05 0+00:01:30 R 0 2.4 condor_dagman -
592.1 |-NodeA 9/13 16:05 0+00:01:24 R 0 0.0 sleep 300
593.1 |-NodeB 9/13 16:05 0+00:01:24 R 0 0.0 sleep 300
594.0 |-SubZ 9/13 16:05 0+00:01:24 R 0 2.4 condor_dagman -
595.1 |-NodeSA 9/13 16:05 0+00:01:18 R 0 0.0 sleep 300
596.1 |-NodeSB 9/13 16:05 0+00:01:18 R 0 0.0 sleep 300
6 jobs; 0 completed, 0 removed, 0 idle, 6 running, 0 held, 0 suspended
And, finally, that state in batch (default) mode:
$ condor_q
-- Schedd: wenger@manta.cs.wisc.edu : <128.105.14.228:9619?...
OWNER BATCH_NAME SUBMITTED DONE RUN IDLE TOTAL JOB_IDS
wenger ex1.dag+591 9/13 16:05 _ 4 _ 5 592.1 ... 596.1
6 jobs; 0 completed, 0 removed, 0 idle, 6 running, 0 held, 0 suspended
condor_q will exit with a status value of 0 (zero) upon success,
and it will exit with the value 1 (one) upon failure.
Center for High Throughput Computing, University of Wisconsin-Madison
Copyright © 1990-2016 Center for High Throughput Computing,
Computer Sciences Department,
University of Wisconsin-Madison, Madison, WI. All Rights Reserved.
Licensed under the Apache License, Version 2.0.
Next: condor_qedit
Up: 11. Command Reference Manual
Previous: condor_procd
Contents
Index