This tutorial has been developed as an interactive introduction to the Stork Data Placement Scheduler, presented as part of Condor Week 2005, March 14 - 18, 2005, at the University of Wisconsin, Madison. In this tutorial you will learn:
Stork is an emerging Condor technology for managing data placement. Stork provides a fault tolerant framework for scheduling data allocation and data transfer jobs. The architecture is modular and extensible, with support for many popular storage systems and data transfer protocols. Simply put, Stork is to data placement jobs, as Condor is to CPU processing jobs. Now, Stork is bundled with the Condor release package. Condor installations can be configured to manage both CPU processing, and data placement jobs. Further, users can manage job dependencies with Condor DAGMan. For more information on Stork, see the Stork Home page: http://www.cs.wisc.edu/condor/stork/.
Students should also have a basic understanding of the Condor distributed job management system. Students new to Condor should consider attending the preceeding Condor User hands on tutorial, prior to attending this tutorial.
The following requirements will not be a concern for students attending this tutorial at Condor Week 2005, but should be verified before running this tutorial at any other time.
This tutorial requires features in v6.7.6 of the Condor developer's release series. These features are not available in the Condor v6.6 stable release series, but are planned for inclusion in the v6.8 stable release series. Stork v6.7.6 is the first Stork release bundled with Condor, and is only compatible with Linux Glibc-2.3 platforms, such as RedHat9. Stork will support additional platforms in future releases of Condor.
Examples in this tutorial require a "personal Stork", that is, a single user installation, (not running as root), with the Stork server running on the local host. The DAGMan examples required access to a Condor installation.
The user's CONDOR_CONFIG environment should specify the correct Condor/Stork configuration file(s). The user's PATH environment should be preconfigured to find all programs executed in this tutorial.
The Original Protocol Retry examples require installation of an instrumented "unreliable" data transfer module, installed as LIBEXEC/stork.transfer.unreliable_ftp-file.
The Job Control examples require the Unix special device file /dev/random.
$ echo This is the Stork tutorial This is the Stork tutorialThis tutorial creates and views several text files. Users typically employ their favorite text editor for this purpose. However, we have found that it is often difficult to standardize upon any single editor in a group tutorial, with students of varying backgrounds. Therefore, this tutorial creates files using the simple Unix cat shell command, like so
$ cat > output_file This is how we create files without an editor Ctrl-DCtrl-D means to momentarily hit both the Ctrl and D keys at the same time. In this tutorial, files are also viewed with the Unix cat shell command, like so
$ cat output_file This is how we create files without an editorStudents who prefer to create and view the example text files with editors available on the instructional computers are welcome to do so. In either case, you should use your mouse to copy the example input into either cat or your editor.
This tutorial makes use of the condor_config_val command, which queries the Condor/Stork configuration files for a requested parameter value. For example, here's a query for the value of the LOG directory, where all Condor and Stork system log files are located.
$ condor_config_val LOG /tmp/cw05-local-dir/log
Several examples are followed by verification steps, to demonstrate the data transfer succeeded. Skeptics are welcome to also perform the verification step before the transfer, in which case the initial verification step should fail.
Each student will be issued a login user name. Login with your assigned user
name to your assigned instructional computer.
After logging into your instructional computer, install and run a Unix shell
script to preconfigure your workspace. You should see the output
Stork tutorial configuration complete
with no accompanying error messages.
$ source /p/condor/workspaces/weber/cw05/stork_tutorial_setup.csh Stork tutorial configuration completeStart up your personal Condor/Stork, using condor_master. This program is the "parent" process for all Condor programs, including Stork.
$ condor_master condor_masterVerify you have access to your personal Stork server with the stork_q command
$ stork_q =============== job queue: =============== ===============There should be no accompanying error messages. We'll learn more about the stork_q command later. For now, we're just using it to verify access to the Stork server.
Verify you have access to Condor with the condor_q command. Again no error messages should accompany this output.
$ condor_q -- Submitter: royal01.cs.wisc.edu : <128.105.112.101:34833> : royal01.cs.wisc.edu ID OWNER SUBMITTED RUN_TIME ST PRI SIZE CMD 0 jobs; 0 idle, 0 running, 0 heldWe are now setup, with a working personal Stork, and ready to proceed with the tutorial.
Stork accesses the local filesystem using the file:/ data protocol. file:/ always refers to the filesystem local to the Stork server host, which is not always the same as the Stork job submit host. However, we are running a "personal Stork" for this tutorial. So all file:/ does refer to the local filesystem on your instructional computer.
We will only be using Stork for data transfers in this tutorial, so we will always specify dap_type = transfer in our Stork submit files.
Stork places no restriction on the submit file name or extension. Stork will accept any valid filename for a submit file.
$ cat > transfer_file-file.stork
[
dap_type = transfer;
src_url = "file:/etc/termcap";
dest_url = "file:/tmp/stork/file-termcap";
]
Ctrl-D
$ cat transfer_file-file.stork
[
dap_type = transfer;
src_url = "file:/etc/termcap";
dest_url = "file:/tmp/stork/file-termcap";
]
Submit this file to Stork using stork_submit:
$ stork_submit transfer_file-file.stork
================
Sending request:
[
dest_url = "file:/tmp/stork/file-termcap";
src_url = "file:/etc/termcap";
dap_type = transfer
]
================
Request assigned id: 1
Note that stork_submit echos the submit file contents (not necessarily
in the same order), and indicates the job id assigned by the Stork
server, which was 1 for this example. The stork_status command
requires a job id as an input parameter.
If your returned job ids differ from
those in the example output, use your job id as input to stork_status.
Let's monitor our job progress using stork_status, furnishing the job id. Use stork_status to monitor the status of any active or completed Stork job id.
$ stork_status 1
===============
status history:
===============
[
status = request_completed;
dap_id = 1;
timestamp = absTime("2005-03-06T20:13:56-0600")
]
===============
As this is a very simple Stork job, it may complete very quickly. Repeat
stork_status as necessary until your job completes.
You can use the Unix sum checksum command to verify the source and destination local files are identical. The values returned by sum are not important. However, both the source and destination files should have the same sum values:
$ sum /etc/termcap /tmp/stork/file-termcap 01763 432 /etc/termcap 01763 432 /tmp/stork/termcap
$ cat > transfer_ftp-file.stork
[
dap_type = transfer;
src_url = "ftp://ftp.cs.wisc.edu/condor/classad/classad-talk.ps";
dest_url = "file:/tmp/stork/classad-talk.ps";
]
Ctrl-D
$ cat transfer_ftp-file.stork
[
dap_type = transfer;
src_url = "ftp://ftp.cs.wisc.edu/condor/classad/classad-talk.ps";
dest_url = "file:/tmp/stork/classad-talk.ps";
]
Submit this file to Stork using stork_submit:
$ stork_submit transfer_ftp-file.stork
================
Sending request:
[
dest_url = "file:/tmp/stork/classad-talk.ps";
src_url = "ftp://ftp.cs.wisc.edu/condor/classad/classad-talk.ps";
dap_type = transfer
]
================
Request assigned id: 2
Monitor your job progress with stork_status until your job request is
completed:
$ stork_status 2
===============
status history:
===============
[
status = request_completed;
dap_id = 2;
timestamp = absTime("2005-03-06T21:19:16-0600")
]
===============
If you like, you can verify receipt of the FTP server classad-talk.ps
file with the GhostView PostScript file viewer:
$ gv -swap classad-talk.psHit the q key to quit GhostView.
Our original example jobs that read the Unix /etc/termap file had the opportunity to complete very quickly. You may only have seen these jobs in the completed state with stork_status. Let's create a long running job which will be easier to monitor before completion. To do this, we need to read from a very large file, but we don't want to unnecessarily load the Stork server host with possibly many active simultaneous large file transfers. The Unix /dev/random file can help us out here. This special device file can supply us with an infinite stream of data, and simulate a large input file. However, reads from this file will halt, when the system runs out of "randomness", which occurs frequently in practice. This behavior is ideal for our tutorial. First, verify the presence of /dev/random:
$ ls -l /dev/random crw-r--r-- 1 root root 1, 8 Jan 30 2003 /dev/randomIf you instead receive a system error message, such as
We will copy the /dev/random file to /dev/null, the Unix "bit bucket". Let's create our Stork submit file:
$ cat > transfer_long.stork
[
dap_type = transfer;
src_url = "file:/dev/random";
dest_url = "file:/dev/null";
]
Ctrl-D
$ cat transfer_long.stork
[
dap_type = transfer;
src_url = "file:/dev/random";
dest_url = "file:/dev/null";
]
Submit this file twice to Stork using stork_submit. Now, Stork
will be processing 2 jobs simultaneously.
$ stork_submit transfer_long.stork
================
Sending request:
[
dest_url = "file:/dev/null";
src_url = "file:/dev/random";
dap_type = transfer
]
================
Request assigned id: 3
$ stork_submit transfer_long.stork
================
Sending request:
[
dest_url = "file:/dev/null";
src_url = "file:/dev/random";
dap_type = transfer
]
================
Request assigned id: 4
We can now use stork_q to query all jobs active for our Stork server.
stork_q does not [yet] have any other command line arguments to
filter job queue output.
stork_q works well when you want to query the entire queue,
or when you don't know any job ids ahead of time. stork_q only
reports on active Stork jobs. The output will be empty if there are no active
jobs. In contrast.
stork_status is able to report on the status of completed jobs,
but requires a job id on the command line. These two tools may be merged in a
future release. stork_q shows two active jobs:
$ stork_q
===============
job queue:
===============
[
dest_url = "file:/dev/null";
src_url = "file:/dev/random";
status = "processing_request";
dap_id = 3;
use_protocol = 0;
dap_type = transfer;
owner = "weber@cs.wisc.edu";
timestamp = absTime("2005-03-08T03:42:55-0600")
]
[
dest_url = "file:/dev/null";
src_url = "file:/dev/random";
status = "processing_request";
dap_id = 4;
use_protocol = 0;
dap_type = transfer;
owner = "weber@cs.wisc.edu";
timestamp = absTime("2005-03-08T03:42:56-0600")
]
===============
Now, we can remove these jobs with the stork_rm command, which
requires a target job id. Remember to remove each job id (dap_id) returned by
stork_q.
$ stork_rm 3 DaP job 3 is removed from queue. $ stork_rm 4 DaP job 4 is removed from queue.Run stork_q again. The queue is empty:
$ stork_q =============== job queue: =============== ===============
One of the primary benefits for using Stork to manage your data placements is Stork's builtin Fault Tolerance. Stork is designed to handle large data sets, and to manage and recover from any data transfer problem that may arrise. If your data transfer fails, Stork can retry the transfer using the same protocol, or using a list of alternate data protocols.
$ ls -lL `condor_config_val LIBEXEC`/stork.transfer.unreliable_ftp-file ls -bF -l /afs/cs.wisc.edu/p/condor/workspaces/weber/cw05/condor-6.7.6/libexec/stork.transfer.unreliable_ftp-file -rwxr-xr-x 1 weber weber 694 Mar 8 14:26 /afs/cs.wisc.edu/p/condor/workspaces/weber/cw05/condor-6.7.6/libexec/stork.transfer.unreliable_ftp-file*If you instead receive a system error message, such as
Create a Stork submit file to invoke the unreliable ftp to file transfer:
$ cat > unreliable_ftp_file.stork
[
dap_type = transfer;
src_url = "unreliable_ftp://ftp.cs.wisc.edu/condor/glidein/condor_config.glidein";
dest_url = "file:/tmp/stork/condor_config.glidein";
]
Ctrl-D
$ cat unreliable_ftp_file.stork
[
dap_type = transfer;
src_url = "unreliable_ftp://ftp.cs.wisc.edu/condor/glidein/condor_config.glidein";
dest_url = "file:/tmp/stork/condor_config.glidein";
]
Submit the unreliable transfer job to Stork:
$ stork_submit unreliable_ftp_file.stork
================
Sending request:
[
dap_type = transfer;
src_url = "unreliable_ftp://ftp.cs.wisc.edu/condor/glidein/condor_config.glidein";
dest_url = "file:/tmp/stork/condor_config.glidein";
]
================
Request assigned id: 5
Repeat either stork_status jobId, or
stork_q until this transfer completes.
$ stork_status 5
===============
status history:
===============
[
dest_url = "file:/tmp/stork/condor_config.glidein";
src_url = "unreliable_ftp://ftp.cs.wisc.edu/condor/glidein/condor_config.glidein";
status = "request_received";
dap_id = 5;
use_protocol = 0;
dap_type = transfer;
owner = "weber@cs.wisc.edu";
timestamp = absTime("2005-03-08T20:16:44-0600")
]
===============
...
$stork_status 5
===============
status history:
===============
[
status = request_completed;
dap_id = 5;
timestamp = absTime("2005-03-08T20:16:45-0600")
]
===============
Now, let's watch the progress of this job in the Stork User Log.
Currently, this file is located in the Condor system LOG directory.
However, this location may change to the user submit directory in a future
release. Use the Unix grep string search utility to search the Stork
user log for all the unreliable_ftp transfers:
$ grep unreliable `condor_config_val LOG`/Stork.user_log
<a n="SrcUrl"><s>unreliable_ftp://ftp.cs.wisc.edu/condor/glidein/condor_config.glidein</s></a>
<a n="DestUrl"><s>file:/tmp/stork/condor_config.glidein</s></a>
<a n="SrcUrl"><s>unreliable_ftp://ftp.cs.wisc.edu/condor/glidein/condor_config.glidein</s></a>
<a n="DestUrl"><s>file:/tmp/stork/condor_config.glidein</s></a>
<a n="SrcUrl"><s>unreliable_ftp://ftp.cs.wisc.edu/condor/glidein/condor_config.glidein</s></a>
<a n="DestUrl"><s>file:/tmp/stork/condor_config.glidein</s></a>
So, the above transfer example failed on the first two attempts, and succeeded
on the third attempt. The unreliable transfer module will succeed
approximately 1 out of 3 transfer attempts. Your transfer may succeed on the
first attempt, or not succeed at all. The Stork server is configured to
abandon a transfer after a predetermined limit, specified in the
STORK_MAX_RETRY configuration parameter. The default value is 10
total transfer attempts. You can repeat this unreliable transfer example
again, if you wish.
where list is a string containing a comma separated list of protocols of the format source-dest. For example, adding this keyword to a Stork submit file directs Stork to do nothing if the original transfer specified in the src_url and dest_url submit file keywords succeeds. However, if the original transfer fails, Stork will retry the transfer first on using the foo:// to file:/ protocol. If that transfer fails, Stork will then retry the transfer using the bar:// to file:/ protocol. It is important to note that for each retry, Stork will vary the protocol, but not the server identified in the source or destination URL. alt_protocols = "foo-file, bar-file";
If none of these transfers succeeds, Stork retries yet again with the original transfer, then proceeds throught the alternate protocol list again, etc. The number of total transfer attempts is limited by the the STORK_MAX_RETRY configuration parameter. The default value is 10. We will create a submit file that downloads the Condor WWW Home Page the hard way: fails on the original ftp:// to file:/ transfer, fails on the first alternate gsiftp:// to file:/ transfer, and finally succeeds on the second alternate http:// to file:/ transfer. We do this by transferring data from a known host that has a web (http) server, but no FTP nor GridFTP server.
$ cat > alt_protocol.stork [ dap_type = transfer; src_url = "ftp://www.cs.wisc.edu/condor/index.html"; dest_url = "file:/tmp/stork/index.html"; alt_protocols = "gsiftp-file, http-file"; ] Ctrl-D $ cat alt_protocol.stork [ dap_type = transfer; src_url = "ftp://www.cs.wisc.edu/condor/index.html"; dest_url = "file:/tmp/stork/index.html"; alt_protocols = "gsiftp-file, http-file"; ]Submit the alternate transfer protocols job to Stork:
$ stork_submit alt_protocol.stork
================
Sending request:
[
dest_url = "file:/TBD/index.html";
alt_protocols = "gsiftp-file, http-file";
src_url = "ftp://www.cs.wisc.edu/condor/index.html";
dap_type = transfer;
]
================
Request assigned id: 6
Repeat either stork_status jobId, or
stork_q until this transfer completes.
$ stork_q
stork_q
===============
job queue:
===============
[
dest_url = "file:/TBD/index.html";
alt_protocols = "gsiftp-file, http-file";
src_url = "ftp://www.cs.wisc.edu/condor/index.html";
status = "request_rescheduled";
dap_id = 1;
use_protocol = 1;
dap_type = transfer;
error_code = "GLOBUS error: globus_xio: A system call failed: Connection refused\n";
num_attempts = 1;
owner = "weber@cs.wisc.edu";
timestamp = absTime("2005-03-09T13:57:42-0600")
]
===============
$ stork_q
stork_q
===============
job queue:
===============
[
dest_url = "file:/TBD/index.html";
alt_protocols = "gsiftp-file, http-file";
src_url = "ftp://www.cs.wisc.edu/condor/index.html";
status = "request_rescheduled";
dap_id = 1;
use_protocol = 2;
dap_type = transfer;
error_code = "GLOBUS error: globus_xio: A system call failed: Connection refused\n";
num_attempts = 2;
owner = "weber@cs.wisc.edu";
timestamp = absTime("2005-03-09T13:57:45-0600")
]
===============
$ stork_q
stork_q
===============
job queue:
===============
===============
Again, let's watch the progress of this job in the Stork User Log.
Use the Unix grep string search utility to search the Stork
user log for all the index.html transfers:
$ grep index.html `condor_config_val LOG`/Stork.user_log
<a n="SrcUrl"><s>ftp://www.cs.wisc.edu/condor/index.html</s></a>
<a n="DestUrl"><s>file:/tmp/stork/index.html</s></a>
<a n="SrcUrl"><s>gsiftp://www.cs.wisc.edu//condor/index.html</s></a>
<a n="DestUrl"><s>file:/tmp/stork/index.html</s></a>
<a n="SrcUrl"><s>http://www.cs.wisc.edu//condor/index.html</s></a>
<a n="DestUrl"><s>file:/tmp/stork/index.html</s></a>
So, the above transfer example
failed on the first attempt with the ftp:// protocol,
failed again on the second attempt with the gsiftp:// protocol,
and succeeded on the third attempt with the http:// protocol. This is
the correct be response, as this host is only running a web server, and not a
ftp or gsiftp server.
You can verify the transfer of the Condor Home Page with your web browser, by clicking here. Use the "back" arrow or button on your browser to return to this tutorial. Alternatively, you can verify the beginning of this file using head
$ head /tmp/stork/index.html <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd"> <!-- - DON'T EDIT THIS! - It's a generated page, you need to edit the source and rebuild - cvs -d /p/condor/repository/HTML co condor-web - cd condor-web - <edit pages under src> - cvs update/commit - generate_html src -->
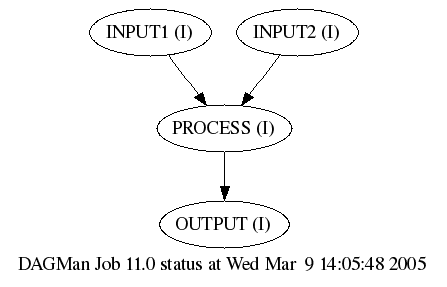
$ cat > stork-condor.dag # This is a sample DAG # # Transfer input files using Stork DATA INPUT1 alt_protocol.stork DATA INPUT2 transfer_ftp-file.stork # # Process the data using Condor JOB PROCESS process.condor # # Transfer output file using Stork DATA OUTPUT transfer.stork # # Specify job dependencies PARENT INPUT1 INPUT2 CHILD PROCESS PARENT PROCESS CHILD OUTPUT Ctrl-D $ cat stork-condor.dag # This is a sample DAG # # Transfer input files using Stork DATA INPUT1 alt_protocol.stork DATA INPUT2 transfer_ftp-file.stork # # Process the data using Condor JOB PROCESS process.condor # # Transfer output file using Stork DATA OUTPUT transfer.stork # # Specify job dependencies PARENT INPUT1 INPUT2 CHILD PROCESS PARENT PROCESS CHILD OUTPUTLet's discuss the contents of this DAG. First, # hash characters are used to start a comment line. The DATA keyword specifies the symbolic name and input file for a Stork data placement job. This DAG has two input files, transferred by the Stork jobs INPUT1, INPUT2. The JOB keyword specifies the symbolic name and input file for a Condor CPU processing job. The Condor job PROCESS reads both the input files. Finally, another Stork job OUTPUT transfers the processed data to the final output destination. This DAG is show graphically
$ /bin/rm -f /tmp/stork/index.html /tmp/stork/classad-talk.ps
Create Condor submit file to perform a merged sort of the input files, using the Unix /bin/sort utility. (It is best to specify executable programs to Condor using absolute paths.) Again, Stork submit file syntax is different from Condor submit file syntax.
$ cat > process.condor universe = vanilla executable = /bin/sort arguments = /tmp/stork/index.html /tmp/stork/classad-talk.ps output = /tmp/stork/process.results.out error = process.results.err log = process.results.log should_transfer_files = YES when_to_transfer_output = ON_EXIT notification = never queue Ctrl-D $ cat process.condor universe = vanilla executable = /bin/sort arguments = /tmp/stork/index.html /tmp/stork/classad-talk.ps output = /tmp/stork/process.results.out error = process.results.err log = process.results.log should_transfer_files = YES when_to_transfer_output = ON_EXIT notification = never queueCondor submit file syntax is beyond the scope of this tutorial. However, it is important to note for our DAG processing, that this Condor job takes the input files /tmp/stork/index.html, /tmp/stork/classad-talk.ps from Stork and processes these with the merged sort utility. The merged sort output is placed in the output file /tmp/stork/process.results.out.
Finally, let's take this data processing output file and transfer it somewhere. For simplicity, let's copy this file to another file in our tutorial directory, howwever, Stork can transfer the processing output with any valid Stork data transfer protocol.
$ cat > transfer.stork
[
dap_type = transfer;
src_url = "file:/tmp/stork/process.results.out";
dest_url = "file:/tmp/stork/process.results.out-copy";
]
Ctrl-D
$ cat transfer.stork
[
dap_type = transfer;
src_url = "file:/tmp/stork/process.results.out";
dest_url = "file:/tmp/stork/process.results.out-copy";
]
Now that we have all the necessary input files, we can submit the DAG file to
DAGMan using the condor_submit_dag command. DAGMan needs to read the
Stork user logs to determine the Stork jobs are complete. There is not [yet] a
default Stork user log location, so we also specify our Stork user log location
to DAGMan on the command line.
$ condor_submit_dag -storklog `condor_config_val LOG`/Stork.user_log stork-condor.dag Checking all your submit files for log file names. This might take a while... Done. ----------------------------------------------------------------------- File for submitting this DAG to Condor : stork-condor.dag.condor.sub Log of DAGMan debugging messages : stork-condor.dag.dagman.out Log of Condor library debug messages : stork-condor.dag.lib.out Log of the life of condor_dagman itself : stork-condor.dag.dagman.log Condor Log file for all jobs of this DAG : /tmp/stork/process.results.log Stork Log file for all DaP jobs of this DAG : /tmp/cw05-local-dir/log/Stork.user_log Submitting job(s). Logging submit event(s). 1 job(s) submitted to cluster 1. -----------------------------------------------------------------------Follow DAGMan's progress with the Unix less utility, on the DAGMan output file. The +F option instructs less to scroll forward, and keep trying to read when the end of file is reached (similar to the Unix tail -f utility). This plays the DAGMan output file like a movie as DAGMan progresses through the DAG. DAGMan is done when the line containing the string
$ less +F stork-condor.dag.dagman.out 3/9 14:05:48 ****************************************************** 3/9 14:05:48 ** condor_scheduniv_exec.11.0 (CONDOR_DAGMAN) STARTING UP 3/9 14:05:48 ** /scratch/weber/install/V6_7-branch/stork-build/local.north/spool /cluster11.ickpt.subproc0 3/9 14:05:48 ** $CondorVersion: 6.7.5 Feb 17 2005 PRE-RELEASE-UWCS $ 3/9 14:05:48 ** $CondorPlatform: I386-LINUX_RH9 $ 3/9 14:05:48 ** PID = 14397 3/9 14:05:48 ****************************************************** 3/9 14:05:48 Using config file: /scratch/weber/install/V6_7-branch/stork-build/e tc/condor_config 3/9 14:05:48 Using local config files: /scratch/weber/install/V6_7-branch/stork- build/local.north/condor_config.local 3/9 14:05:48 DaemonCore: Command Socket at <128.105.146.21:33035> 3/9 14:05:48 argv[0] == "condor_scheduniv_exec.11.0" ... 3/9 14:06:27 Of 4 nodes total: 3/9 14:06:27 Done Pre Queued Post Ready Un-Ready Failed 3/9 14:06:27 === === === === === === === 3/9 14:06:27 4 0 0 0 0 0 0 3/9 14:06:27 All jobs Completed! 3/9 14:06:27 **** condor_scheduniv_exec.11.0 (condor_DAGMAN) EXITING WITH STATUS 0Take less out of movie mode by hitting Ctrl-C which means to momentarily hit both the Ctrl key and C key at the same time. Then quit less by hitting the q key.
Proficient less users are welcome to scroll up and down in the file to view DAGMan's progress. Here's a summary of what should happen:
$ cat process.results.out-copy
...
TeXDict begin
TeXDict begin /SDict 200 dict N SDict begin /@SpecialDefaults{/hs 612 N
TeXDict begin /rf{findfont dup length 1 add dict begin{1 index /FID ne 2
TeXDict begin /setcmykcolor where{pop}{/setcmykcolor{dup 10 eq{pop
TeXDict begin 52099146 40258431 2074 600 600 (classad-talk.dvi)
The first three days of Condor/Paradyn week (March 14-16, 2005) will
The goal of the Condor Project is to develop, implement, deploy, and evaluate me
...
Stork modules are typically installed in the LIBEXEC Condor installation directory. You can see which modules are installed in your Stork installation with the Unix shell command
$ ls `condor_config_val LIBEXEC`/stork.*Currently, the file:/ to file:/ data transfer protocol is distributed with Stork. Additionally, contributed modules for the following data protocols are available from the Stork home page.
| ftp:// | file transfer protocol |
| gsiftp:// | GridFTP |
| http//: | hypertext transfer protocol |
| nest//: | Condor NeST network storage |
| srb//: | SDSC storage resource broker |
| srm//: | dCache SRM |
| csrm//: | Castor SRM |
| unitree//: | NCSA UniTree |
| diskrouter//: | Condor DiskRouter |
stork.type.protocol1[.protocol2]
type can be one of transfer, reserve, release. protocol1indicates the module protocol, or the source URL protocol for transfer modules. protocol2indicates the destination URL protocol for transfer modules. An example will illustrate. The module
stork.transfer.gsiftp-file
transfers data from the gsiftp:// protocol to the file:// protocol. This modular interface can be exploited by sites to suit their own needs. As an example, we crafted an "unreliable" ftp:// to file: module, named stork.transfer.unreliable_ftp-file in the Fault Tolerance tutorial examples.
All transer modules are invoked with these arguments:
moduleName src_url dest_url [arguments]
src_url is taken from the corresponding src_url submit file keyword. dest_url is taken from the corresponding dest_url submit file keyword. arguments is taken from the corresponding arguments submit file keyword, if this keyword is present.
Stork fully supports GridFTP transfers, with the gsiftp:// protocol. To use GridFTP with Stork, users must first create an X.509 proxy, using grid-proxy-init from the Globus toolkit. Specify the path to the created proxy using the x509proxy keyword in the Stork submit file. (Future versions of Stork may not require an explicit proxy path, and may search for the user proxy in the standard locations.) Alternatively, Stork can retrieve a X.509 proxy from the Condor Credential Manager, below. In this case, specify Credential Manager proxy credential name using the cred_name submit file keyword. Stork will then retrieve the proxy from the Credential Manager to authenticate to the GridFTP server.