Snap Together Motion
Download the paper (PDF)
Summary
We present an approach to character
motion called Snap-Together Motion that addresses the unique demands
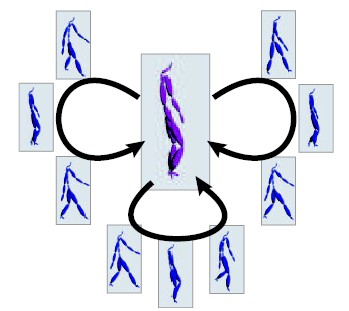
of virtual environments. Snap-Together Motion (STM) preprocesses
a corpus of motion capture examples into a set of short
clips that can be concatenated to make continuous streams of motion.
The result process is a simple graph structure that facilitates
efficient planning of character motions. A user-guided process selects
"common" character poses and the system automatically synthesizes
multi-way transitions that connect through these poses. In
this manner, well-connected graphs can be constructed to suit a particular
application, allowing for practical interactive control without
the effort of manually specifying all transitions.
The following video clip shows overview of our approach.

(AVI, 15 MB, 0:51)
Graph Construction
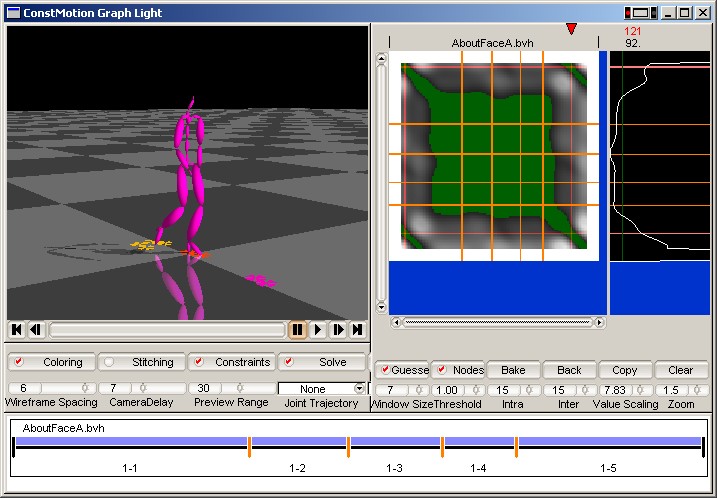
In this work we focus on providing users with a user-interface to construct a motion graph with "hub nodes"
which have a large number of incoming and outgoing edges based on a corpus of motion capture data.
The following video demonstrates our interface of graph construction:
(AVI, 25 MB, 1:21)
To construct a graph, our system first let users choose a base frame.
The based frame is selected by users based on their a priori knowledge or by system based on heuristic.
Once a base frame is chosen, our system automatically selects a set of similar frames called match frames.
To compute similarity between two frames, we use the distance metric proposed by Kovar et al. which is based on point cloud matching.
Our system then computes the average pose for the match frames using the coordinate frame matching technique , and the quaternion averaging technique. The average pose is copied to every match frame to make motion snappable while keeping kinematic constraints preserved and guaranteeing C1 continuity in the resulting transitions.
Run-time Motion Synthesis
At run-time, virtual environment applications can synthesize a high-quality motion with a little overhead.
Every motion clip stores the starting and ending nodes and coordinate transformation to align the next motion together with the motion data itself. Therefore, the run-time application is able to produce
a stream of motion by concatenating the motion clips with the proper coordinate transformations.
The following video clips exhibit the resulting motions at run-time:

(AVI, 12MB, 0:40)
-
This video shows the motion generated with a motion graph based on a corpus of walking motion.
(AVI, 10MB, 0:32)
- Next is a second example from a corpus of martial arts motions. Here, our system automatically chose
left and right stance poses of martial arts as hub nodes.

(AVI, 16MB, 0:38)
-
Finally, a graph is constructed using both walking and martial arts motions which are obtained from different sources.