
Virtual Videography
People
Michael Gleicher, Assistant
Professor
Michael Wallick, Graduate Student
Rachel Heck, Graduate Student
Summary
The main idea behind Virtual Videography is to automatically edit video of some event that would be nice to record, but too costly or intrusive to place a camera crew. Currently, our project is looking at the domain of classroom chalkboard lectures. We choose this area simply because we have access to a large set of lectures, and can always record more (being at a University). In the future we will look at other events, such as professor office hours, and group meetings. All of the processing is done off-line, which allows us to spend more time processing the video [than an on-line system], and create special effect shots.
Movies
Demonstration of Virtual Videography, approximatey 5 minutes with sound, and 86 megabytes. We submitted a smilar video for SIGGRAPH 2004 (added 1/28/04). NOTE: Compressed with Microsoft MPEG4 v1
Demonstration of Virtual Videography,
approximately 6 minutes with sound, and 26 megabytes. We submitted a similar
video for SIGGRAPH 2003.
Above video - one half resolution,
approximately 6 minutes with sound, and 10 megabytes.
(Note: Both videos require the DIVX
CODEC in order to play properly.)
Computer Vision
The project is roughly broken into two parts. The first part uses computer vision to mine as much information from the video as possible, and being to create. Some of the information that is extracted is a tracker of the professor, and a clean plate version of the chalkboard (remove the professor) at every frame.
Another major component of the computer vision section is "Region Finding." That is, finding the areas of the chalkboard that have writing on it, grouping these areas together, and knowing when it was first written on, and when it was erased. These regions can serve as a basis for composing shots later on.
Other tasks that the computer vision section is concerned with, looks at the professor. This includes tracking the professor in the shot, determining his or her orientation and gesture recognition
The information that is extracted is then collected together for use in the next section, which looks at
(Above): A picture of found regions. The colors correspond to the age of each region
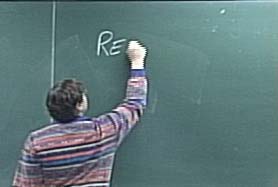

(Left) Picture of the professor writing on the chalkboard. (Right) Same image after the professor has been removed
Computational Cinematography
The second part of Virtual Videography is what we call Computational Cinematography. During the Computational Cinematography phase of the project, the information gathered from the first phase is used to make decisions about how to edit the data of the lecture.
First, a model is used to approximate the focus of the lecture. Specifically, heuristics based on classroom lectures are used to determine whether there is a particular region of the chalkboard that is a likely focus for every point in time.
Next, the sequence of edited shots is chosen globally using the vision information, the focus information, and the rules of cinematography.
Finally, this sequence of shots is rendered to produce the final video of the lecture.
Publications
Michael Gleicher Rachel Heck Michael Wallick. A Framework for Virtual Videography. Smart Graphics. June 2002.
Michael Gleicher and James Masanz. Towards Virtual Videography.
ACM Multimedia 2000, Los Angeles, CA. November, 2000.
Funding
Virtual Videography is supported in part by National Science Foundation grants CCR-9984506 and IIS-0097456 and equipment donations by Intel, IBM, and NVidia.
This page is maintained by Michael Wallick.
Send comments, suggestions and spelling corrections to michaelw@cs.wisc.edu.
Last Update: 27 Jan 2003
Minor Corrections: 29 Jan 2003
Pointers to newer pages: 17 December 2015