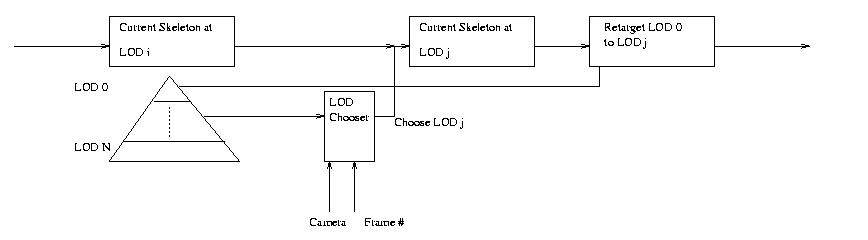
Figure 1
Traditionally, choosing between multiple Levels of Detail (LOD) of a model is a common technique for improving the performance in real time animation systems. The main idea is to not expend rendering resources on model detail when the details cannot be perceived. Such scenarios arise when a model is too far from the viewer or the time to focus on the model is too short.
While using only geometric LOD's is the norm, what becomes of the LOD of motion data? Of the many issues involved, we consider how to help a user construct multiple geometric LOD for a given model and how to automatically retarget the motion data of the original model to the new LODs.
Such techniques are expected to be especially useful for animations requiring many models and in an environment covering a large space. Concrete examples include stadium crowds, city freeways, or marching columns. As a result, we also handle cloning and displacement of models.
We address the above issues by extending our Motion Capture Tool. The modifications are focused on how a user introduces LOD to an existing model and given these new LODs, how the system automates their usage to produce an animation that is as close to the original model's animation but with significant simplifications in the model and its motion. In addition, the internal representations have been modified to allow for rendering multiple types of models and clones of each model placed at an arbitrary starting location. The latter is helpful in evaluating the choices made in automating LOD usage and in general is useful for composing more complex scenes.
In order to study motion LOD, a method is required to introduce multiple LODs for a given model. When considering either motion or geometric LOD, either an automatic or manual process can be used. While a signal processing approach may be a reasonable approach to generating motion LOD, we choose a more geometric approach, that is we simplify by removing a joint thus removing its associated motion data. The problem then is reduced to picking the right joints to remove from the model. Since there are no known prior works, automating this step would introduce too many variables so we instead provide a tool the user can use to simplify the skeleton manually and produce an ordering in terms of complexity among the produced LODs. This process is known as Skeleton Editing at the end of which is a set of (or pyramid) of LODs for a given skeleton that can be written out in BVH format.
The next stage in considering motion LOD is how to use the newly created LOD for a given skeleton in an animation. The first problem that arises is given a current camera position relative to a skeleton, what LOD should be used. We abstract this decision through an LODChooser class that takes a skeleton, its pyramid of LODs, the camera, and the current frame and picks an appropriate LOD. Next, given the chosen LOD render it. However, since motion data may now be missing, the skeleton's end effectors may end up in drastically different locations than the original skeleton's motion. Therefore, prior to rendering, the skeleton's motion data must pass through a fix-up stage which is essentially a retargeting problem from one skeleton to another. Since resizing is not an issue, we approach the problem by trying to get the end effectors as close to the original end effectors as possible. Two retargeters are implemented and compared: one based on geometric retargeting and the other based on Inverse Kinematics. The process of choosing an LOD and possibly retargeting the motion is referred to as the LOD pipeline which constitutes the automation of LOD handling if present in a skeleton.
In order to evaluate the above process, the Motion Capture tool has been extended to handle multiple skeletons, each with its own LOD pyramid, and the capability to clone a skeleton, its pyramid, and place it arbitrarily in the scene. Furthermore, different LODChoosers and Retargeters can be swapped in dynamically into each such skeleton in a scene for comparison purposes.
The remainder of the report details the primary components of the LOD Motion extensions along with examples of animation from the system that illustrate the process and the effects of decisions made in the LOD pipeline. Since the project has an open ended scope, interesting things to do but beyond our time limitations came up so they are listed in the Future Works section.
Given our limited time frame, we did not experiment with any automated technique for producing the skeletons. Rather, we implemented a tool that allows the animator to load an existing skeleton and use it as a starting point for creating the different LOD's. The tool uses a tree-based visualization of the skeleton, and allows the user to alter the geometry by removing joints. When a joint is removed, the tool updates the offsets of the children joints so that their position relative to the grandparent joint remains the same. The user creates new LOD's by cloning existing skeletons, and can also specify the elevation of each new LOD. When all the LOD's have been created, the user can export the result in a file.
The editing tool reads and exports files in the BVH format. The export file contains an hierarchy of multiple skeletons, each skeleton corresponding to a different LOD. The root joints of the skeletons carry one additional channel for the elevation of the skeleton, and all joints have an additional id channel. The id channel is used to map similar joints in different skeletons and is used mainly for retargeting the original motion. Using the id channel, for example, the retargeting module can identify the joint of the left hand in two different LODs. Although this encoding is not optimal, we chose to represent LOD information in channels so that the export file could still be parsed by a conventional BVH parser.
Given a skeleton and its associated pyramid of LODs, prior to rendering, it passes through an LOD Pipeline whose goal is to find the simplest good LOD and fix its motion if need be. The primary units that do this work are the LODChooser and Retargeter. The LODChooser picks the best LOD of the skeleton according to some strategy. Since the LOD chosen need not look right with the original motion data applied to it, the original motion is retargeted to the new model. At the end of the pipeline, the appropriate LOD will have been chosen along with the necessary corrections. All scene skeletons will first pass through such a pipeline and subsequently rendered. The pipeline is shown in Figure 1.
Since a chosen LOD may not have a 1-1 a mapping with the original motion data, the motion must be retargeted to the newly selected LOD. Consider the end effector of a skeleton's arm when it is tucked into its chest. Assume now that the elbow joint is removed, resulting in a long stiff arm. If we apply the same rotations to the shoulder joint as the original skeleton, the arm will end outstretched, leaving the end effector in a drastically different location. Even if the resolution is low when this LOD is chosen, such poor end effector mappings on many skeletons in a scene may yield undesirable artifacts.
Since the skeletons differ in the number of joints and not in their translational components, the retargeting considers only joint and rotational re-mappings between source and target skeletons. The target is clearly the new LOD but what about the source skeleton? The choices that seemed most reasonable are the original LOD and the previously used LOD. The original LOD was chosen as the source for all retargeting since the latter requires either more storage or recomputation and more importantly, did not seem convincingly better to warrant abandoning a simpler solution.
Due to the many decision needed for retargeting strategies in the design, we settled on two: geometric retargeting and IK retargeting. Both find a correspondence between source and target joints followed by respectively a translational approach and a rotational approach.
The retargeting algorithm is pretty straightforward. First, all joints that have different parents in the two skeletons are identified; these will be the joints that the algorithm will attempt to retarget. Then, for each such joint in the target skeleton, the algorithm computes a local translational component that will compensate for the rotations of the missing parent joint.
This technique guarantees that all joints will end up in the same position as in the original skeleton, which might be important if the character is interacting with other objects in the scene (i.e. holding an object, or shaking hands with another character). On the other hand, care must be taken when defining the LOD's and their elevation levels, so that the viewer does not perceive the varying length of the limbs.
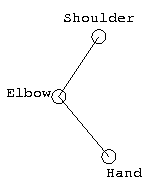 |
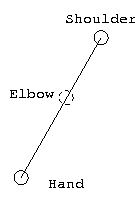 |
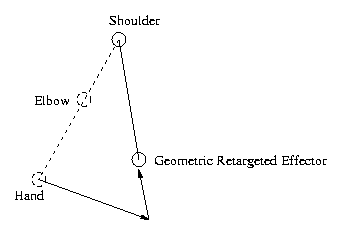 |
| Original Skeleton | Target Skeleton | Geometrically Retargeted End Effector |
|
|
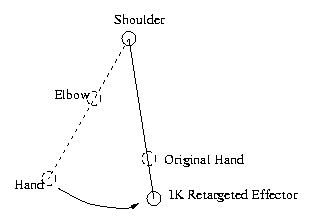 |
| Original Skeleton | Target Skeleton | IK Retargeted End Effector |
The following movies show the motion of the different LOD skeletons using the geometric and the IK retargeting method.
Note that the skeletons are viewed at a close range and therefore their motion and structure are strikingly different. The LOD skeletons, however, will be used when the original skeleton appears far in the scene. The following movies compare the LODs and their motion when they are located far from the camera.In this case, the LOD motions appear more plausible since the details and differences are not so readily perceivable.
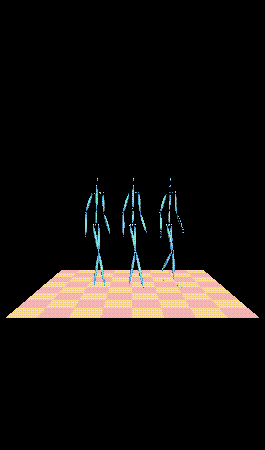 Original Skeleton, First LOD
with Geometric Retargeting, First LOD with IK
Retargeting (right to left)
Original Skeleton, First LOD
with Geometric Retargeting, First LOD with IK
Retargeting (right to left)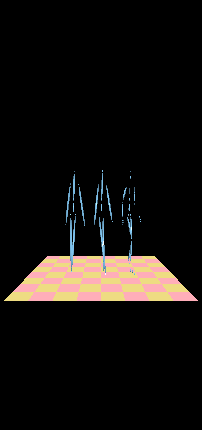 Original Skeleton, Second LOD
with Geometric Retargeting, Second LOD with IK
Retargeting (right to left)
Original Skeleton, Second LOD
with Geometric Retargeting, Second LOD with IK
Retargeting (right to left)The final set of movies shows the transitions between the different levels as the distance from the camera changes. Although the transition from the original skeleton to the first LOD seems smooth, the transition from the first to the second LOD is abrupt. This can be remedied by recalibrating the elevation levels of the skeletons, or by morphing the transitions. The latter would require solving a complex IK system so that the end effectors would be located in the same position while missing joints would gradually "vanish" with the appropriate rotations.
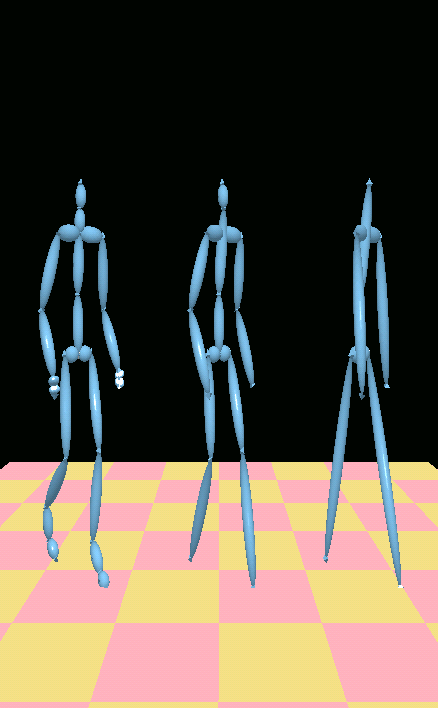 Geometric Retargeting
Geometric Retargeting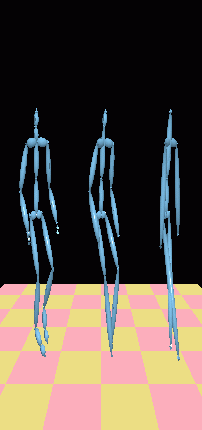 IK Retargeting
IK Retargeting Geometric Retargeting
Geometric Retargeting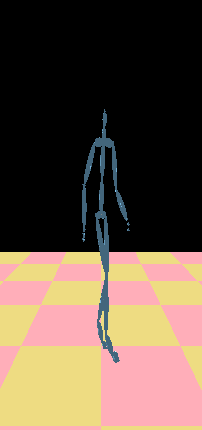 IK Retargeting
IK Retargeting