Note: I still have to change some of the text.
Here are some example queries and plans to demonstrate some of the different points of the Minibase optimizer. In the examples given, we have four different joins available: tuple-oriented nested loops, page-oriented nested loops, index nested loops, and sort-merge. The catalog used contains the following two tables:
emp 5 2000 36 50 empid 1 I 0 999999999 4 0 1 B_Index 23 A 1 0 2000 1 2 emp-B_Index-empid ename 2 T A Z 20 4 1 Hash 1 R 1 0 2000 1 1 emp-Hash-ename dno 3 I 0 999999999 4 24 1 Hash 1 R 1 0 2000 1 1 emp-Hash-dno jno 4 I 0 999999999 4 28 1 B_Index 23 A 1 0 2000 1 2 emp-B_Index-jno sal 5 I 0 999999999 4 32 2 B_Index 23 A 1 0 2000 1 2 emp-B_Index-sal FileScan 50 R 0 dept 2 2000 24 50 dno 1 I 0 999999999 4 0 1 Hash 1 R 1 0 2000 1 1 dept-Hash-dno dname 2 T A Z 20 4 1 FileScan 50 R 0
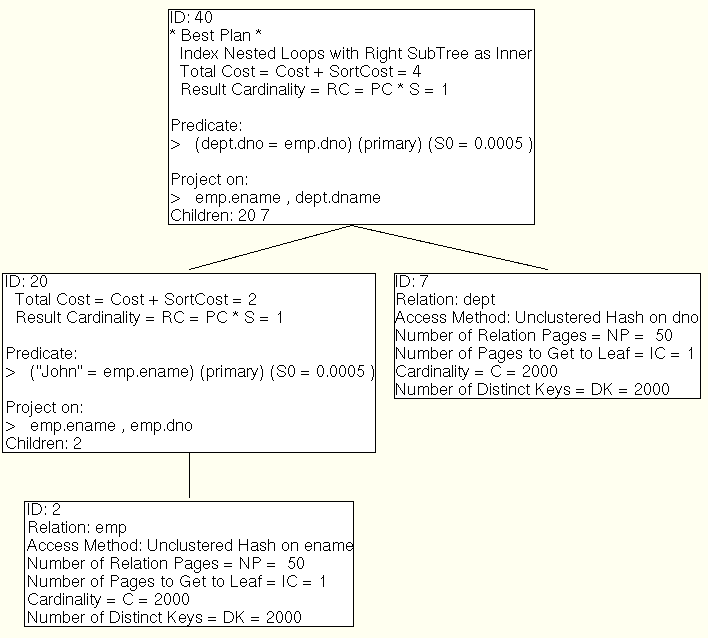
select ename, dname from emp, dept where ename = "John" and
emp.dno = dept.dno;
Minibase Optimizer output
Click here for the iterator tree
Fairly straight forward join. Does not (and can not) be index only on any index.
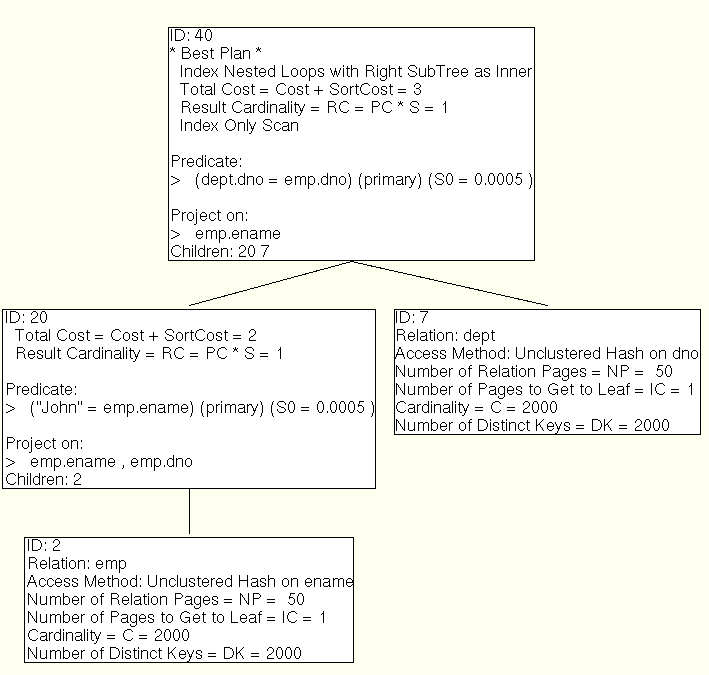
select ename from emp, dept where ename="John" and emp.dno=dept.dno;
Minibase Optimizer output
Click here for the iterator tree
Index only at the join, since we aren't using anything from dept except for a selection that matches the index.
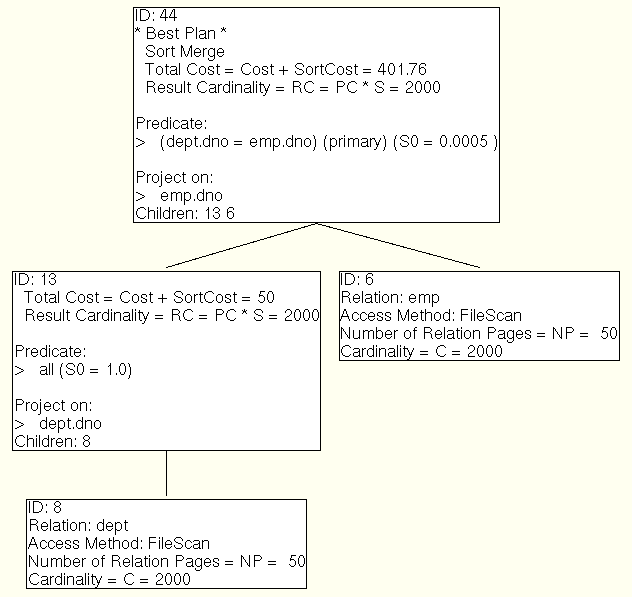
select emp.dno from emp, dept where emp.dno = dept.dno
Minibase Optimizer output
Click here for the iterator tree
Note, if we supported index only scans on hash indicies this could be different. If you look at the output, you'll notice that the left subtree outputs very few pages, so a sort is very inexpensive. (Sorts are only costed on basis of page I/O's, so it will only cost 1 to sort one page).

select emp.dno, dept.dname from emp, dept where emp.dno = dept.dno
Minibase Optimizer output
Not currently supported by the backend.
In this case, it is not advantageous to use an index. The reason for this is that it will cost one I/O per tuple with the index match, but significantly fewer with a simple nested loops.