The ADvanced Systems Laboratory (ADSL)
Publication abstract
| :: | Home |
| :: | Projects |
| :: | People |
| :: | Pictures |
| :: | Publications |
| :: | Software |
| :: | Sponsors |
| :: | Internal |
|
Protocol- and Situation-Aware Distributed Storage Systems
Ramnatthan Alagappan
|
Abstract:
We are dependent upon data in many aspects of our lives. Much of this data is stored and managed by distributed storage systems that run in data centers, powering many modern applications such as e-commerce, photo sharing, video streaming, search, social networking, messaging, collaborative editing, and even health-care and financial services.
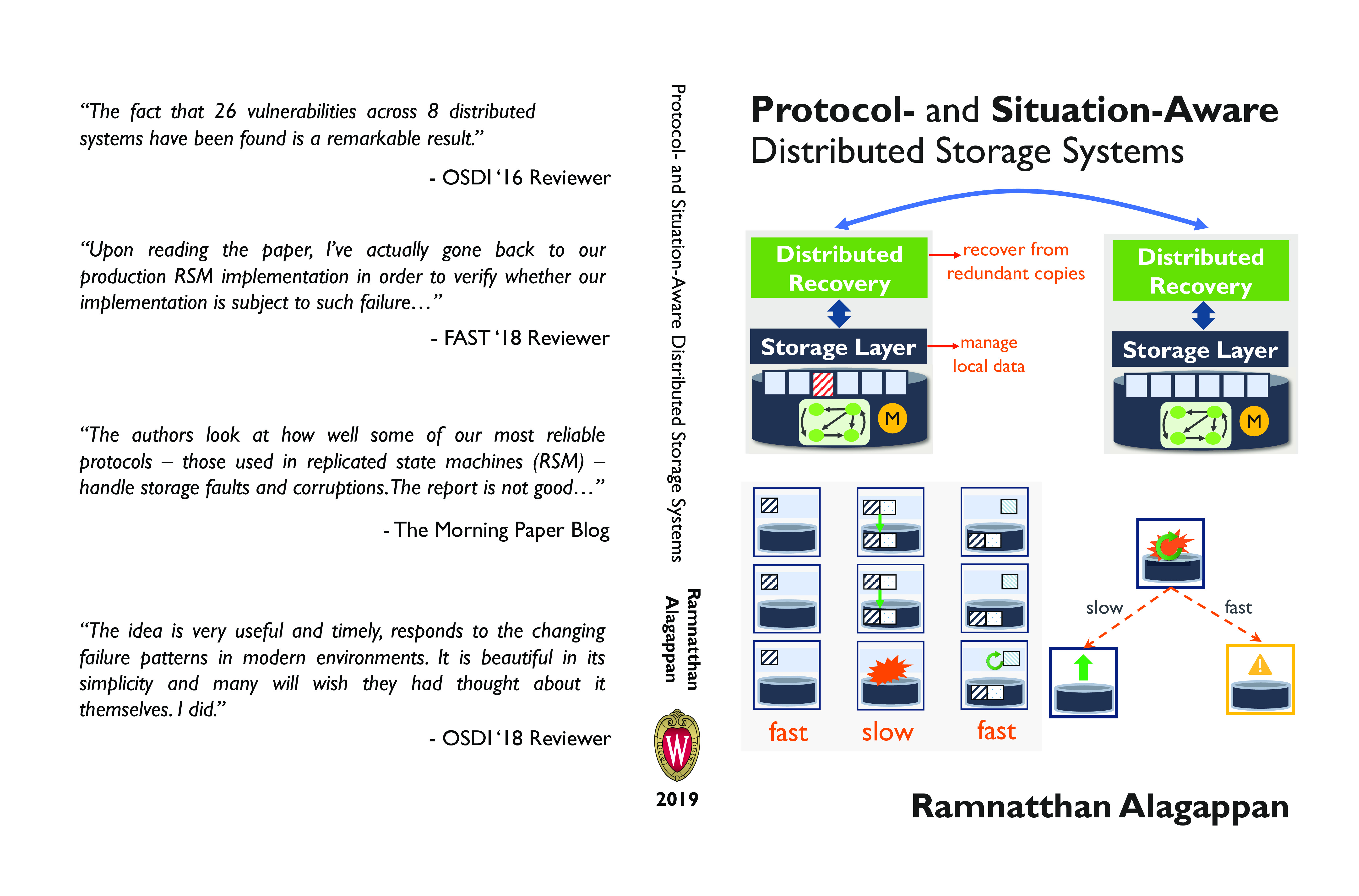
A distributed storage system stores copies of a piece of data on many nodes for fault-tolerance: even when a few nodes fail, the system can still provide access to data. Each of these nodes depends upon a local storage stack to safely store and manage user data. The local storage stack is complex, consisting of many hardware and software components. Due to this complexity, the storage layer is a place for many potential problems to arise. This dissertation examines the reliability and performance challenges that arise the interaction points between a distributed system and the local storage stack.
In the first part of this thesis, we study how distributed storage systems react to storage faults: cases where the storage device may return corrupted data or errors. We focus on replicated state machine systems, an important class of distributed systems. We find that none of the existing approaches used in current systems can safely handle storage faults, leading to data loss and unavailability. Using the insights gained in our study, we design corruption-tolerant replication (Ctrl), a protocol-aware recovery approach for RSM systems. Ctrl exploits protocol-specific knowledge of how RSM systems operate, to ensure safety and high availability in the presence of storage faults without impacting performance.
In the second part, we study the performance and reliability properties of replication protocols used by distributed systems. We find there exists a dichotomy with respect to how and where current approaches store system state. One approach writes data to the storage stack synchronously, whereas the other buffers the data in volatile memory. The choice of whether data is written synchronously to the storage device or not greatly influences the system’s robustness to crash failures and its performance. We show that existing approaches either provide robustness to crashes or performance, but not both. Thus, we introduce situation-aware updates and crash recovery, a dynamic protocol that, depending upon the situation, writes either synchronously or asynchronously to the storage devices, achieving both strong reliability and high performance.
In the final part of this thesis, we study the effects of file-system crash behaviors in distributed storage systems. We build protocol-aware crash explorer or Pace, a tool that can model and reason about file-system crash behaviors in distributed systems under a special correlated crash failure scenario. Our study reveals that the correctness of update and recovery protocols of many distributed systems hinges upon how the local filesystem state is updated by each replica. We perform a detailed analysis of the vulnerabilities, showing their serious consequences and prevalence on commonly used file systems. We finally point to possible solutions to the problems discovered.
Full Paper:
PDF
BibTeX
Publications