First, change into a directory with the example job:
% cd ~/examples/dagman
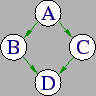
The DAG we will use involves 4 jobs: A, B, C and D. They are in a
simple 3-tier dependency: A is the parent. B and C both depend on A.
D depends on B and C. Represented graphically, the dependency looks
like this:
Job A will run a program called "random", which will generate a random number and print it to STDOUT. We'll print A's output to "A.out". (Note: we generate a random even number, since we want it to be evenly divisible by two).
Jobs B and C will both run the same program, "half", which will read a number in from STDIN, divide it by 2, and print the result to STDOUT. Both B and C will be submitted so that they read STDIN from the output of job A, "A.out", and each will print their own output to B.out and C.out respectively. Once they complete, since they're both doing the same thing to the same input, they should both generate the same output.
Job D will run a program called "sum". Sum expects to see filenames given to it as command-line arguments. For each filename it is passed, it will open the file, read out an integer, and add the number to a total. Once it is out of files, it will print out the total to STDOUT. We will pass "B.out" and "C.out" as arguments to job D, and put its output into "D.out".
Each job in the DAG must have its own submit file. For us, they are simply named "job.submit", for example, "A.submit", "B.submit", etc. All the submit files must share the same UserLog entry, so that DAGMan can properly monitor them. We use "diamond.log" for this.
If you would like, you can examine the different submit files:
% cat A.submit % cat B.submit % cat C.submit % cat D.submit
Now, let's look at the DAG description file, "diamond.dag":
% cat diamond.dag
It has only 3 parts: a comment at the top, a section where it names each job in the DAG and associates a submit file with each one, and the section that gives the dependencies between the jobs.
Now, we must build all the programs and link them with condor_compile. To make this step easier, there's a Makefile in your directory, so you just have to type "make":
% make
Now, we're ready to actually submit the DAG to Condor. We do this with the condor_submit_dag command, which works like condor_submit, except it is looking for a DAG description file, not an individual Condor job description file:
% condor_submit_dag diamond.dag
This will check your diamond.dag file for errors. In particular, it looks at all the submit files you reference, and makes sure they all use the same log entry. You will notice in the output a line that looks like this:
Condor Log file for all jobs of this DAG : diamond.log
This means that we got it right. Finally, condor_submit_dag will submit a copy of condor_dagman as a "scheduler universe" job. This means that the condor_schedd will execute condor_dagman for us, and pass in the right arguments so that it runs our DAG. The output from condor_submit is passed on to us, and you'll see the cluster number for the condor_dagman itself printed out.
If you run condor_q, you should see at least 1 job, in the "R" state, which is DAGMan itself. In addition, you might see job A already submitted, "random.condor"
% condor_q
You should continue to run condor_q to follow the progress of your DAG. At first, you will see just "random.condor". Once that completes, you should soon see two copies of "half.condor" submitted into the queue.
% condor_q
Once both of those complete, you should see "sum.condor" submitted to the queue.
% condor_q
Once sum.condor has completed, both it and the condor_dagman job should both leave the queue and condor_q should yield "0 jobs".
% condor_q
Now, lets examine all the output to make sure everything worked. First, lets see the random number we started with:
% cat A.out
Now, lets see if half.condor did the right thing:
% cat B.out % cat C.out
Both of these files should have the same number in them, which should be 1/2 of what we got in A.out. Finally, lets see if sum.condor was correct:
% cat D.outThis should be the same exact value that we started with in A.out. Let's check this with cmp:
% cmp A.out D.out
"cmp" should produce no output if the files are the same.
Now, let's look at the last 5 entries in condor_history to see all the jobs of our DAG (yes, 5 jobs, because there were 4 in the DAG, as well as condor_dagman itself):
% condor_history | tail -5
Notice that the very last entry is from a cluster that has the lowest cluster number. This is the condor_dagman job itself. The 4 entries above it each have higher cluster numbers, since they were submitted by condor_dagman (which must have been after condor_dagman itself was submitted!). However, condor_dagman exited last, since only after all the jobs in the DAG complete can condor_dagman actually exit. (Note: jobs B and C, "half.condor" might not have finished in numerical cluster order, since they were submitted at the same time. However, both of them definitely completed after "random.condor" and before "sum.condor" finished).
As a final step, let's take a look at diamond.log, to see exactly what happened. You might want to use "less" so you can scroll up and down with your arrow keys. To exit less, just type "q":
% less diamond.log
This file is written for other parts of Condor to understand, as well as for humans. So, the format will take a brief explaination. The first column should just be ignored (it tells Condor what kind of log entry follows). The second column is a job ID that says which job this entry is for. In this file, it has the form: (cluster.proc.000). For example, job 23.0 would be: "(023.000.000)". Next, comes a timestamp for the entry, so you know when the entry happened. Finally, there's some text that gives the human-readable explaination of what happened, along with important data (for example, what machine a job started executing on).
In your log, the first thing you should see is an entry for when job A was submitted. The only way to tell which job is which is by the Job ID, which we just saw with condor_history.
Next, you should see an entry for when job A started running, followed by the entry for when job A completed. After that, there should be two submit entries, for jobs B and C. Then you'll see entries for when B and C started running, and when they completed (again, these entries could be in a number of different orders). Once both B and C completed, you'lll see an entry for when D was submitted, when it ran, and when it completed.
That's it, we're done!